
[ad_1]
Introduction
NLP (Natural Language Processing) can help us understand large amounts of textual data. Instead of manually skimming and reading documents manually, we can use this technique to speed up our understanding and get to key messages quickly. In this blog post, we explore the possibility of using Panda data frameworks and NLP tools in Python to gain insight into what people were writing about gender equality research in Afghanistan using Elicit. These insights can help us understand what has worked and what hasn’t to advance gender equality in recent decades in a country considered one of the most difficult places for women and girls (World Economic Forum, 2023).
learning objective
- Gain knowledge for text analysis in CSV files.
- Learn how to do natural language processing in Python.
- Developing effective data visualization skills for communication.
- Learn how research on gender equality in Afghanistan has evolved over time.
This article was published as part of the Data Science Blogathon.
Using Elicit for literature review
To generate key data, I use Elicit, an AI-powered tool from Literature Reviews (Elicit). I am asking the tool to generate a list of papers related to the question: Why has gender equality failed in Afghanistan? I then download the resulting list of papers (I count a random number of papers over 150) in CSV format. What does this data look like? Let’s take a look!
Parsing CSV data from Elicit in Python
We will first read in the CSV file as a pandas dataframe:
import pandas as pd
#Identify path and csv file
file_path="./elicit.csv"
#Read in CSV file
df = pd.read_csv(file_path)
#Shape of CSV
df.shape
#Output: (168, 15)
#Show first rows of dataframe
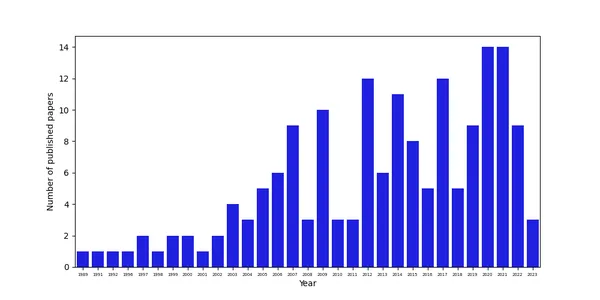
df.head()The df.head() command displays the first rows of the resulting pandas dataframe. The data frame consists of 15 columns and 168 rows. We create this information with the df.shape command. Let us first examine the year in which most of these studies were published. To explore this, we can use a column that shows the year each article was published. There are several tools for generating figures in Python, but let’s rely on sea and the matplotlib library. To analyze in which year the papers were mostly published, we can use the so-called countplot and also make the axis labels and axis ticks look nice:
Timely distribution analysis of published papers
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#Set figure size
plt.figure(figsize=(10,5))
#Producte a countplot
chart = sns.countplot(x=df["Year"], color="blue")
#Set labels
chart.set_xlabel('Year')
chart.set_ylabel('Number of published papers')
#Change size of xticks
# get label text
_, xlabels = plt.xticks()
# set the x-labels with
chart.set_xticklabels(xlabels, size=5)
plt.show()The data show that the number of papers has increased over time, probably also due to the availability of more data and better opportunities to conduct research in Afghanistan since the Taliban fell from power in 2001.
Content analysis of papers
Number of words written
While this gives us a first glimpse of research on gender equality in Afghanistan, we are mostly interested in what the researchers actually wrote about. To get an idea of the content of these papers, we can use the abstract that Elicit has kindly included in the CSV file of the tool we created. To do this, we can follow standard text analysis procedures, such as those outlined by Jan Kierentz in one of his blog posts. We start by simply counting the number of words in each abstract using the lambda method:
#Split text of abstracts into a list of words and calculate the length of the list
df["Number of Words"] = df["Abstract"].apply(lambda n: len(n.split()))
#Print first rows
print(df[["Abstract", "Number of Words"]].head())
#Output:
Abstract Number of Words
0 As a traditional society, Afghanistan has alwa... 122
1 The Afghanistan gender inequality index shows ... 203
2 Cultural and religious practices are critical ... 142
3 ABSTRACT Gender equity can be a neglected issu... 193
4 The collapse of the Taliban regime in the latt... 357
#Describe the column with the number of words
df["Number of Words"].describe()
count 168.000000
mean 213.654762
std 178.254746
min 15.000000
25% 126.000000
50% 168.000000
75% 230.000000
max 1541.000000big. Most abstracts seem to be rich in words. They have an average of 213.7 words. The minimum abstract consists of only 15 words, while the maximum abstract contains 1541 words.
What do the researchers write?
Now that we know that most abstracts are rich in information, let’s ask what they mainly write about. We can do this by doing a frequency distribution for each written word. However, we are not interested in certain words such as stopwords. Accordingly, we need to process the text:
# First, transform all to lower case
df['Abstract_lower'] = df['Abstract'].astype(str).str.lower()
df.head(3)#import csv
# Let's tokenize the column
from nltk.tokenize import RegexpTokenizer
regexp = RegexpTokenizer('\w+')
df['text_token']=df['Abstract_lower'].apply(regexp.tokenize)
#Show the first rows of the new dataset
df.head(3)
# Remove stopwords
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
# Make a list of english stopwords
stopwords = nltk.corpus.stopwords.words("english")
# Extend the list with your own custom stopwords
my_stopwords = ['https']
stopwords.extend(my_stopwords)
# Remove stopwords with lampda function
df['text_token'] = df['text_token'].apply(lambda x: [item for item in x if item not in stopwords])
#Show the first rows of the dataframe
df.head(3)
# Remove infrequent words (words shorter than or equal to two letters)
df['text_string'] = df['text_token'].apply(lambda x: ' '.join([item for item in x if len(item)>2]))
#Show the first rows of the dataframe
df[['Abstract_lower', 'text_token', 'text_string']].head()What we do here is convert all words to lower case and later tokenize them using natural language processing tools. word tokenization is a crucial step in natural language processing and involves dividing text into individual words (tokens). we use RegexpTokenizer and tokenize the text of our abstracts based on alphanumeric characteristics (referred to as: ‘\w+’). Save the obtained marks in the column text_token. We then extract terms from this list using the natural language processing toolbox dictionary nltk, the Python NLTK (Natural Language Toolkit) library. Delete words that are shorter than two letters. This type of text processing helps us focus our analysis on more important terms.
Create a Word Cloud
To visually analyze the resulting list of words, we create a list of strings from the text we processed and tokenize this list and then create a word cloud:
from wordcloud import WordCloud
# Create a list of words
all_words=" ".join([word for word in df['text_string']])
# Word Cloud
wordcloud = WordCloud(width=600,
height=400,
random_state=2,
max_font_size=100).generate(all_words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off');
The word cloud shows that the mentioned words are mostly those that are also part of our search query: Afghanistan, gender, gender equality. However, some other words that are substitutes are also part of the list of the most mentioned words: women and men. These words themselves are not very informative, but some others are: within the framework of research on gender equality in Afghanistan, researchers seem to be very concerned about education, human rights, society and the state. Surprisingly, Pakistan is also part of the list. This may mean that the results generated by the search query are inaccurate and also include research on gender equality in Afghanistan, although we did not ask for it. Alternatively, they could mean that the gender equality of Afghan women is also an important research topic in Pakistan, perhaps because many Afghans have settled in Pakistan as a result of the difficult situation in their country.
Analyze the moods of the authors
Ideally, the research will be neutral and free from emotions and opinions. However, it is in our human nature to have opinions and sentiments. To investigate the extent to which researchers reflect their own sentiments in what they write about, we can do a sentiment analysis. Sentiment analysis is a method to analyze a set of text as positive, neutral or negative. In our example, we will use the VADER sentiment analysis tool. VADER stands for Valence Aware Dictionary and Sentiment Reasoner and is a A vocabulary and rule-based sentiment analysis tool.
How the VADER sentiment analysis tool works is that it uses a pre-built sentiment vocabulary consisting of a large number of words with associated sentiments. It also provides grammatical rules to reveal the sentimental polarity (positive, neutral and negative) of short texts. The tool provides a sentiment score (also called a composite score) based on the sentiment of each word and the grammatical rules of the text. This score ranges from -1 to 1. Values above zero are positive and values below zero are negative. Since the tool relies on a pre-built sentiment vocabulary, it does not require complex machine learning models or extensive models.
# Access to the required lexicon containing sentiment scores for words
nltk.download('vader_lexicon')
# Initializes the sentiment analyzer object
from nltk.sentiment import SentimentIntensityAnalyzer
#Calculate the sentiment polarity scores with analyzer
analyzer = SentimentIntensityAnalyzer()
# Polarity Score Method - Assign results to Polarity Column
df['polarity'] = df['text_string'].apply(lambda x: analyzer.polarity_scores(x))
df.tail(3)
# Change data structure - Concat original dataset with new columns
df = pd.concat(
[df,
df['polarity'].apply(pd.Series)], axis=1)
#Show structure of new column
df.head(3)
#Calculate mean value of compound score
df.compound.mean()
#Output: 0.20964702380952382The code above generates a polarity score that ranges from -1 to 1 for each abstract, referred to here as the composite score. The mean value is greater than zero, so most of the research has a positive connotation. How has it changed over time? We can simply define the sentiments by year:
# Lineplot
g = sns.lineplot(x='Year', y='compound', data=df)
#Adjust labels and title
g.set(title="Sentiment of Abstract")
g.set(xlabel="Year")
g.set(ylabel="Sentiment")
#Add a grey line to indicate zero (the neutral score) to divide positive and negative scores
g.axhline(0, ls="--", c="grey")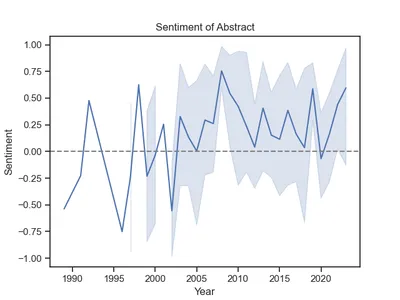
interesting. Most research has been positive since 2003. Prior to that, sentiment fluctuated more sharply and was more negative on average, perhaps due to the plight of women in Afghanistan.
conclusion
Natural language processing can help us extract valuable information from large amounts of text. What we learned here from the nearly 170 papers is that education and human rights were the most important topics in the research papers collected by Elicit, and that researchers began to write more positively about gender equality in Afghanistan after the fall of the Taliban in 2003. in 2001.
Key Takeaways
- We can use natural language processing tools to get a quick insight into the main topics studied in a particular research area.
- Word Cloud is a great visualization tool for understanding the most frequently used words in a text.
- Sentiment analysis shows that the survey may not be as neutral as expected.
I hope this article was informative. Feel free to connect with me on LinkedIn. Let’s connect and work on using data forever!
Frequently Asked Questions
A. Elicit is an online platform designed to help researchers find AI papers and research data. By simply asking a research question, Elicit uses a huge database of 175 million articles to uncover relevant answers. Additionally, it provides the functionality to use Elicit to analyze your own papers. In addition, Elicit boasts a user-friendly interface that ensures effortless navigation and accessibility.
A. Natural Language Processing (NLP) is a specialized branch in the field of Artificial Intelligence (AI). Its primary goal is to enable machines to understand and analyze human language, allowing them to automate a variety of repetitive tasks. Some common NLP applications include machine translation, summarization, ticket classification, and spell checking.
A. There are several approaches to calculating a sentiment score, but a widely used method involves using a dictionary of words classified as negative, neutral, or positive. The text is further examined to determine the presence of negative and positive words, which allows an assessment of the overall mood conveyed by the text.
A. A complex score is obtained by summing the valence scores of individual words in the dictionary, taking into account the applicable rules, and subsequently normalizing the score in the range of -1 (a very negative mood indicator) and +1 (an extremely positive mood indicator) ). This metric is especially valuable when looking for a singular, one-dimensional measure of sentiment.
References
Media displayed in this article is not owned by Analytics Vidhya and is used at the discretion of the author.
connected
[ad_2]
Source link