
[ad_1]
Although I am from India and my mother tongue is Bengali and I speak, read and write both Hindi and Bengali almost as well as English, I have worked exclusively in English in my Natural Language Processing (NLP) career. This is probably not uncommon, as until recently English was the language in which most NLP work was done and, to a lesser extent, some of the major European languages (Spanish, French, German, Russian, etc.). Fortunately or unfortunately, among those languages, English was the only one I knew well enough to work with.
As NLP work with European languages became more widespread, I secretly envied my European colleagues being multilingual in the “correct” languages. The rise of CJK (Chinese, Japanese, Korean) that followed (and its impact on NLP in CJK languages) also largely passed me by because I knew none of those languages. Lately though, I’ve been encouraged by the growth of NLP in Indian languages (languages spoken in India), if only because it has given me hope that I can finally put my multilingual skills to some use :-).
Indian languages are generally considered low-resource languages because there was not enough material to prepare NLP models in electronic format, even though most of them individually have a fairly rich and developed literature. This has changed (or largely eased) with the rise of the internet and social media, with Indian people rediscovering their roots and starting to communicate in their native languages. Software infrastructure to support this, such as the Avro keyboard, has also helped, making it easier to start electronic communication using non-English languages.
At least I saw it This tweet Invite people who spoke Bengali to a decentralized learning experiment organized by Neuropark, Hugging Face and Yandex Research to prepare the ALBERT model for Bengal. Participants needed access to Colab and an Internet connection. I was interested in the distributed training part, and since I met the prerequisites, I decided to participate in the experiment. That was a week and a half ago, training ended today (Friday). In this post, I describe what I learned from the experience.
The objective was to train a large model of ALBERT from scratch in Bengali. The ALBERT transformer model was proposed in ALBERT: A Lite BERT for self-learning language representations in 2019 by Lan et al. It is based on the BERT transformer model, but has fewer parameters and better performance on many benchmark tasks. The stages of training are as follows.
- Bengali Tokenizer Training.
- ALBERT Bengali Language Model (LM) Training.
- Evaluate the model both subjectively and using the task below
Tokenizer training
The tokenizer was trained on the Bengali subset of the multilingual OSCAR database. The text was normalized using the following normalizer pipeline: NMT, which converts different gaps between words into simple spaces; NFKC, which does the magic of Unicode (see below), combining character encodings; A small case that doesn’t affect Bengali much because it doesn’t have letters, but helps embedded English text and various regexes, including converting a sequence of spaces to a single space. The unigram language model algorithm (see Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)) wqs is used for tokenization.
The open source Bengali NLP library BNLP was used for sentence segmentation in the model training stage (see below). The team also tried BLTK, another Bengali NLP library, but ultimately went with BNLP after testing results from both.
An earlier version of the tokenizer was trained using data extracted from various Bengali language websites through the Bakya project and used Byte Pair Encoding (BPE), but this was not used in the final training. In my original post I mistakenly assumed that this was the tokenizer being used for training.
Work around normalization happened before I joined the project, but I was there when there was a request to check the quality of sentences tokenized using BNLP vs. BLTK. That’s when I realized that the team actually needed the Bengals readers Rather than speakers and (mistakenly in my case at least) assuming that the latter automatically implies the former. Growing up outside of Bengal, I learned Hindi as a second language in school, so while I can read Bengali (learned at home), I’m not as fluent in it as I am in Hindi.
I also learned another interesting thing about Bengali (and probably other Indian languages) character representation, probably related to the Unicode magic around NFKC, that I’d like to share here. In English, the 26 letters of the alphabet are combined in different ways to make words. The Bengali alphabet (as in Hindi and possibly other Indian languages derived from Sanskrit) has 7 consonant clusters with 5 characters. Each group makes a sound that uses a specific part of your vocal apparatus (lips, tongue and roof of the mouth, throat, etc. There are also 14 vowel symbols that are used to replace consonant sounds to make words. Unlike English, vowels overlap consonants in the same symbol position. In addition , pairs of consonants can be joined to form new characters that represent a transition sound — this is called a युक्टाक्षर (pronounced juktakkhor) or a joined word.
Anyway, it turns out that Unicode elegantly handles both overlapping vowels on consonants and combining two consonants to form a third, as the following code snippet shows (probably easier to see for a Bengali reader, others will need a bit of wrangling to get it).

Model training
The model was trained on Bengali Wikipedia text and the Bengali portion of the OSACAR dataset. The trained model was the AlbertForPreTraining model from Hugging Face. ALBERT uses two pre-training targets. The first is masked language modeling (MLM) similar to BERT, where we mask 15% of the tokens and let the model learn to predict them. The second is Sentence Order Prediction (SOP), which in the case of BERT tries to predict whether one sentence follows another, but in the case of ALBERT uses segments of text instead of sentences and is considered more efficient than BERT SOP.
The training was conducted in a distributed manner using Yandex Research’s Hivemind project. This project allows a central team to create a training script and have volunteer members online (like me) run it on a subset of the data using free GPU-enabled Colab and Kaggle notebooks. I believe Hivemind can extend training to hybrid non-cloud GPU instances as well as non-free cloud instances, but this was not used here. Once started, a training script on a particular Colab or Kaggle notebook will run until the user stops it or the platform decides to time them out, either due to policy (Kaggle allows a maximum of 9 hours of continuous GPU usage) or inactivity. The training scripts can be found in the github repository mryab/collaborative-training.
Volunteers must participate in the training by adding themselves to the permission list (on request via the Discord channel) and signing up for a Hugging Face account. When starting an instance, they authenticate themselves with a Hugging Face username and password. Each notebook functions as a peer in a decentralized training configuration, training the model locally and generating local updates against the model, and logging its progress using the Weights and Biases (wandb) API. At the end of each training step, the peer group’s notebooks share model parameters (model averages) with each other using a process called all-butterfly reduction. After each successful training round, peers mingle and find new groups to join. This ensures that local updates are propagated to all peers over time. If a peer leaves the group, it affects only the immediate peer group, the remaining members of which will reassemble into other running peer groups.
For a more technical coverage of the distributed training algorithm, please see Moshpit SGD: Efficient Decentralized Training for Communication on Heterogeneous Untrusted Devices (Ryabinin et al, 2021) and its predecessor Crowdsourced Learning Using Decentralized Deformation of Large Neural Networks. (Ryabinin and Gusev, 2020).
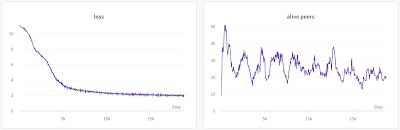
At the start of training, the model was reporting a loss of about 11, which dropped to below 2 after a week and over 20,000 training steps, as shown in the left curve below. The live peers on the right show the number of concurrent workouts per week. At peak there were about 50, which fluctuated between 20 and 40 during training. The gradual drop at the end of training can be at least partially attributed to volunteers exhausting Kaggle quotas (30 GPU hours per week) and being penalized by Colab for hogging CPU resources.
Model evaluation
Of course, for a language model like Bengali ALBERT, a better metric than the loss reduction from 11 to 1.97 is how well it performs at some downstream task. During the training of the model, its checkpoints were subjected to two forms of evaluation.
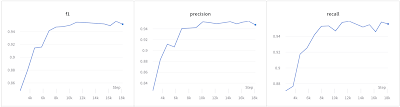
First, the model was specified for the NER task (WikiNER) using the Bengali subset of the multilingual Wiki-ANN dataset, annotating the dataset with LOC (location), PER (person), and ORG (organization) tags. IOB format. Plots below of precision, recall, and F1 values by model checkpoint during training. Final scores were 97.5% precision, 95.6% F1, 95.4% precision, and 95.8% recall.
Additionally, model checkpoints were used to test the model’s ability to predict masked words in the given sentences. This evaluation was more subjective in nature, manually looking at the top 5 masked word predictions of the given sentences and checking their relevance, but it was observed that the final model predicted almost perfect masked words compared to previous checkpoints with more variable behavior.
conclusion
This experience was of great educational value for me. I got to use and see distributed learning environments up close, and I got to interact with a lot of very smart and dedicated developers, researchers, and collaborators who I won’t name because I’m sure I’m forgetting someone. I also saw a lot of code that I’m sure I’ll use for inspiration later. For example, I’m also embarrassed to say that this was my first experience using the Weights and Biases (wandb) API, but I liked what I saw, so I plan to use it in the future.
Also, the progress made in Bengali NLP (and other Indian languages) has been a real eye opener for me. In fact, the current model is not even the first transformer-based model for Bengal, there is already a multilingual IndicBERT that has shown promising results on some tasks. However, this is the first transformer-based model for Bengal that was trained in a distributed manner.
The model (probably named SahajBERT) and the tokenizer will soon be available on Hugging Face. I will provide links to them as they become available.
Finally, many thanks to Nilavya Das, Max Ryabinin, Tanmoy Sarkar, and Lucile Saulnier for their valuable comments and fact-checking of a draft version of this post.
Updates (2021-05-24)
- Updated description of the tokenizer learning process.
- Added links to papers that provide more information on the distributed training approach.
Update (2021-06-01) — The trained tokenizer and model described above have been published and are now available at neuropark/sahajBERT on the Huggingface models site.
[ad_2]
Source link