
[ad_1]
In July of this year, our group on the TWIML Slack Channel got together and participated in the Flax/JAX Community Week organized by Hugging Face and Google Cloud. Our project was about refining OpenAI’s CLIP model with RSICD (Remote Sensing Image Captioning Dataset) and took third place.
The project code is available on github at arampacha/CLIP-rsicd if you’re interested in how we did it, or if you want to replicate our efforts. Our refined model is available in the Hugging Face model repository flax-community/clip-rsicd-v2, where you can find instructions on how to use it for your own remote sensing / satellite data inference. We also have a Streamlit-based demo that demonstrates its use in image search and finding features in images using text descriptions. Finally, we also have a blog post on the Hugging Face blog called Fine tuning CLIP with remote sensing (satellite) images and captions. Hope this is helpful, check them out.
Even before this project, I considered studying the co-embedding of medical images and their captions, as described in Zhang et al.’s Contrastive Learning of Medical Visual Representations of Images and Text (CONVIRT) paper (2010) and using a text-to-image search application. However, based on the RSICD project, CLIP appeared to be a better and modern alternative.
Elsevier has a Dev-10 program for their engineers, where they are given 10 work days (2 weeks) to build something that doesn’t necessarily fit the company’s goals, but is somewhat related to the job. When my Dev-10 day came around in early September, I used it to specify the same OpenAI CLIP baseline as we did for Flax/JAX Community Week, but with the ImageCLEF 2017 Image Captioning dataset. Fortunately, the results were as encouraging as his RSICD refinement, if anything, the improvement was even more significant.
During the RSICD fine-tuning exercise, fine-tuning was done by other team members. My contribution to this project was a grading framework, an image enhancement piece, a demo, and a later blog post. I was the only developer on the ImageCLEF exercise, so while much of the code in the second case was borrowed or adapted from the first, there were some significant differences other than the dataset.
First, in the RSICD specification we used JAX/Flax with a TPU enabled instance on Google Cloud, and in the second I used Pytorch on a single GPU EC2 instance on AWS (Deep Learning AMI). I found that the Hugging Face wrapper for CLIP provides a lot of support for what was done explicitly, so I tried to make the most of the functionality provided, resulting in somewhat cleaner and readable code (even if I do say so myself :-)).
Second, I didn’t do image or text enhancement like we did when trying to specify RSICD. RSICD had a total of 10k images with about 5 labels per image, of which we used about 7k for training. On the other hand, ImageCLEF was about 160k images and captions, of which we used 140k for training. Additionally, RSICD was trained on a TPU with 4 parallel devices, while ImageCLEF was trained on a single GPU. Because of this, I ended up using subsamples from the training set as a form of regularization, and used an early stop to stop the training process as soon as no improvement in validation accuracy was seen.
Third, out of foresight, I settled on a more industry standard metric for evaluation, Average Response Rank (MRR@k) compared to the less strict and somewhat ad-hoc Hits@k metric I used for the first exercise. .
And fourth, because my second Image Search demo data volume was much larger (200k images instead of 10k), I switched to using NMSLib on Vespa, an open source hybrid vector + text search engine from Yahoo! . Using it, I was able to provide image search results based on lexical matches between query and caption text, lexical matches between CLIP query vector and CLIP image vectors, and rank hybrid search results by combining the two approaches’ relevance.
Unfortunately I can’t share the code. Since the work was done on company time with company resources, the code rightfully belongs to the company. I also hope that the work can be used to enhance image search (or related) functions in some production applications. For these reasons I cannot share the code, but in general it is similar (with the differences listed above) to the RSICD version.
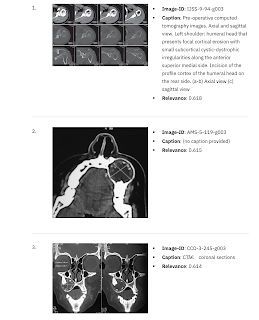
However, just to give you an idea of the kind of results you can expect from a well-tuned CLIP model, here are some screenshots. Results are for the questions “computed tomography” and “computed tomography deep vein thrombosis”. Both results are vector matched, i.e. ranked by the cosine similarity between the CLIP encoding of the query text and the CLIP encoding of each image.
 |
 |
As you can see, CLIP returns relevant images for both high-level and detailed queries, indicating how rich the embedding is. My main takeaways from this series of exercises are two-fold – first, CLIP collaborative image-to-text coding is a seriously powerful idea and is super efficient, and second, transformer models trained on generic data (in this case natural images and text) can. be efficiently tailored for specialized domains using relatively small amounts of data.
[ad_2]
Source link