
[ad_1]
Natural Language Processing (NLP) research has largely focused on developing methods that work well in English, despite the many positive benefits of working in other languages. These benefits range from large social impact to modeling the richness of linguistic features, avoiding overfitting, as well as interesting challenges for machine learning (ML).
About 7000 languages are spoken in the world. The map above (see interactive version on Langscape) gives an overview of languages spoken around the world, with each green circle representing a native language. Most of the world’s languages are spoken in Asia, Africa, the Pacific region, and the Americas.
Although we have seen exciting progress in many natural language processing tasks in recent years (see Papers in Code and NLP Progress for an overview), most such results have been achieved in English and a small set of other high-resource languages.
In a previous review of our ACL 2019 Guide to Unsupervised Language Representation Learning, I defined a hierarchy of resources based on the availability of unlabeled data and labeled data online. In a recent ACL 2020 paper, Josh et al. Define taxonomy similarly based on data availability, which can be found below.
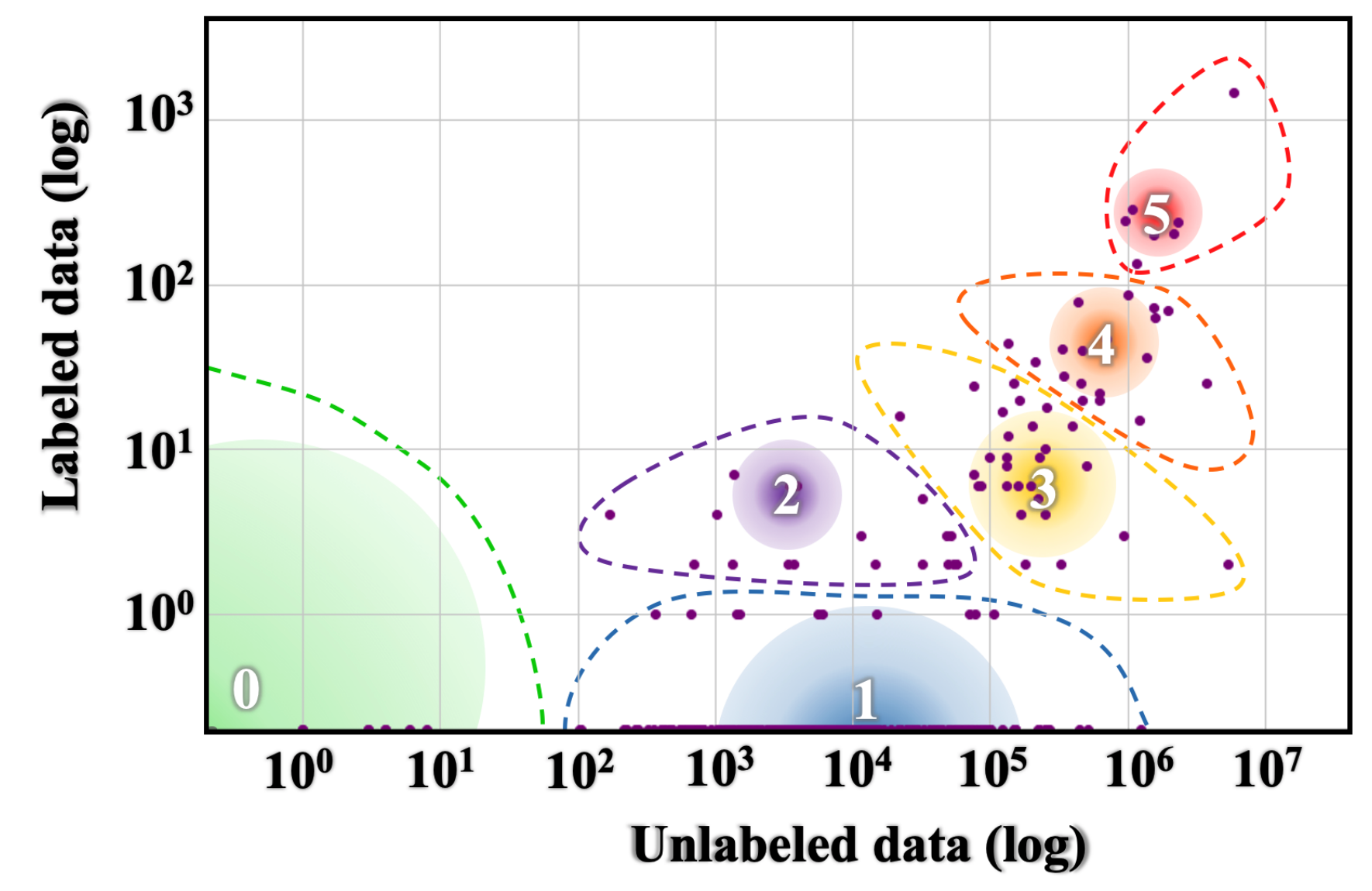
Category 5 and Category 4 languages, which have large amounts of labeled and unlabeled data, are well studied in the NLP literature. On the other hand, the languages of other groups are largely neglected.
In this post I will argue why you should work in languages other than English. Specifically, I identify reasons from social, linguistic, machine learning, cultural and normative, and cognitive perspectives.
A social perspective
The technology will not be available if it is only available to English speakers with a standard accent.
What language you speak determines your access to information, education and even human connections. Although we think of the Internet as open to all, there is a digital language divide between the dominant languages (mostly from the Western world) and others. Only a few hundred languages are represented on the Internet, and speakers of minority languages are severely limited in the information available to them.
Because many more languages are written in informal contexts in chat apps and social media, this divide extends across all levels of technology: at the most basic level of language technology, low-resource languages lack keyboard support and spell-checking (Soria et al. , 2018)—and keyboard Support is even rarer for languages that do not have a widespread written tradition (Paterson, 2015). At a higher level, the algorithms are biased and discriminate against non-English speakers or simply with different accents.
The latter is a problem because most existing work treats a high-resource language such as English as homogeneous. Our models are therefore under-represented in the multiplicity of related linguistic sub-communities, dialects and accents (Blodgett et al., 2016). In fact, the boundaries between linguistic varieties are much more blurred than we imagine, and the linguistic identification of similar languages and dialects is still a difficult problem (Jauhiainen et al., 2018). For example, although Italian is the official language in Italy, there are approximately 34 regional languages and dialects spoken throughout the country.
A continued lack of technological inclusion will not only exacerbate the language divide, but may also drive speakers of underserved languages and dialects to higher-resourced languages with better technological support, further endangering linguistic varieties. To ensure that non-English speakers are not left behind, and at the same time to redress the existing imbalances, reduce language and literacy barriers, we must apply our models to non-English languages.
A Linguistic Perspective
Although we claim to be interested in developing general methods for language understanding, our methods are generally applicable to only one language, English.
English and a small set of other high-resource languages are in many ways unrepresentative of the world’s languages. Many resource-rich languages belong to the Indo-European language family, are mainly spoken in the Western world, and are morphologically poor, i.e. information is mainly expressed syntactically, e.g. word level.
For a more holistic view, we can look at the typological features of different languages. The World Atlas of Language Structure catalogs 192 typological features, i.e. structural and semantic features of the language. For example, one typological feature describes the typical order of subject, object, and verb in a language. Each feature has an average of 5.93 categories. 48% of all feature categories exist only in the low-resource languages of groups 0–2 above and cannot be found in languages of groups 3–5 (Joshi et al., 2020). Ignoring such a large subset of typological features means that our NLP models are potentially missing valuable information that could be useful for generalization.
Working in languages other than English can also help us gain new knowledge about the relationship between the world’s languages (Artetxe et al., 2020). Rather, it will help us clarify what linguistic features our models can capture. Specifically, you can use your knowledge of a particular language to explore aspects different from English, such as the use of diacritics, extensive conjugation, inflection, derivation, reduplication, agglutination, fusion, etc.
The ML perspective
We encode assumptions into the architecture of our models based on the data we intend to use. Although we intend our models to be general, many of their inductive biases are specific to English and related languages.
The lack of any explicitly encoded information in a model does not mean that it is truly language agnostic. A classic example is n-gram language models, which perform significantly worse for languages with sophisticated morphology and relatively free word order (Bender, 2011).
Similarly, neural models often ignore the complexities of morphologically rich languages (Tsarfaty et al., 2020): subword tokenization works poorly in reduplicative languages (Vania and Lopez, 2017), byte-pair encoding does not match morphology well (Bostrom and Durrett). , 2020) and languages with larger vocabularies are more difficult for language models (Mielke et al., 2019). Differences in grammar, word order, and syntax also pose problems for neural models (Ravfogel et al., 2018; Ahmad et al., 2019; Hu et al., 2020). Furthermore, we generally assume that preformed embeddings easily encode all relevant information, which may not be the case for all languages (Tsarfaty et al., 2020).
The above problems pose unique challenges for structure modeling—both at the word and sentence level—in terms of sparsity, learning multiple hits, encoding relevant information in preformed representations, and transfer between related languages, among other areas of interest. These challenges are not addressed by current methods and therefore require a new set of cognitive language approaches.
More recent models have repeatedly matched human-level performance on increasingly complex criteria—that is, using English-labeled data sets with thousands and unlabeled data with millions of examples. In the process, as a society, we are becoming too familiar with the characteristics and conditions of English-language data. In particular, by focusing on high-resource languages, we have derived prioritization methods that perform well only when large amounts of labeled and unlabeled data are available.
In contrast, most modern methods break down when applied to the data-sparse conditions common to most of the world’s languages. Even recent advances in pre-training language models that dramatically reduce sample complexity for downstream tasks (Peters et al., 2018; Howard and Ruder, 2018; Devlin et al., 2019; Clark et al., 2020) require a large number of Clean, labeled data that is not available for most of the world’s languages (Artetxe et al., 2020). Doing well with small data is thus an ideal setting to test the limitations of current models, and evaluation in low-resource languages is likely to be its most influential real-world application.
A cultural and normative perspective
The data our models are trained on reveals not only specific language characteristics, but also sheds light on cultural norms and common sense knowledge.
However, such common sense may be different for different cultures. For example, the concept of “free” and “not free” varies between cultures, where a “free” good is something that anyone can use without permission, for example, salt in a restaurant. Taboo topics are also different in different cultures. In addition, cultures differ in their assessment of relative power and social distance, among many other things (Thomas, 1983). Furthermore, many real-world situations, such as those included in the COPA database (Roemmele et al., 2011), do not match the direct experience of many and do not equally reflect the basic situations that are clearly background knowledge for many people in the world. (Ponty et al., 2020).
Therefore, an agent exposed only to English data originating from the Western world may be able to converse reasonably with speakers from Western countries, but conversation with a person from another culture may lead to pragmatic failure.
Beyond cultural norms and common sense knowledge, the data we build our model on also reflects the underlying societal values. As an NLP researcher or practitioner, we must ask ourselves whether we want our NLP system to exclusively share the values of a particular country or language community.
Although this decision may be less important for current systems that mainly deal with simple tasks such as text classification, it will become more important as systems become more intelligent and require complex decision-making tasks.
A cognitive perspective
Humans can acquire any natural language, and their language comprehension skills are remarkably consistent across all types of languages. To achieve human-level language understanding, our models must be able to show the same level of consistency across languages from different language families and typologies.
Our models should eventually be able to learn abstractions that are not specific to any language structure, but can be generalized to languages with different properties.
What can you do?
data set If you create a new dataset, save half of your annotation budget for creating a dataset of the same size in another language.
Rate If you are interested in a specific task, consider evaluating your model for the same task in another language. For an overview of some of the tasks, see NLP Progress or our XTREME benchmark.
Bender’s rule Specify the language in which you work.
Assumptions Be clear about what signals your model uses and the assumptions it makes. Think about which ones are specific to the language you’re learning and which ones might be more general.
Language diversity Assess the linguistic diversity of the sample of languages you study (Ponti et al., 2020).
Research Work on methods that address the challenges of low-resource languages. In the next post, I will outline interesting research directions and opportunities in multilingual NLP.
Quote
For attribution in an academic context, please cite this paper as:
@miscruder2020beyondenglish,
author = Ruder, Sebastian,
title = Why You Should Do NLP Beyond English,
year = 2020,
howpublished = \urlhttp://ruder.io/nlp-beyond-english,
Thanks to Aida Nematzadeh, Laura Rimel, and Adhi Kunkoro for valuable feedback on drafts of this post.
[ad_2]
Source link