
[ad_1]
Web scraping is the act of magic to extract information from a web page. You can do it on one page or millions of pages. There are many reasons why scraping is essential in SEO:
- We may use it to audit the website
- We may need it in the context of programmatic SEO
- We may use it to provide context for our web analytics
Here at WordLift, we focus primarily on structured data and improving the data quality of content knowledge graphs. We depend on the crawler to deal with missing and dirty data for various use cases.
Extracting structured data from web pages using large language models
Recently, I have been exploring the potential OpenAI function call for that Extracting structured data from web pages. This could be a game changer for those like us who are actively trying to synergize large language models (#LLMs) with knowledge graphs (#KGs).
Why is this exciting? As the integration of LLMs with KGs is fast becoming a hot topic in technology, developing a unified framework that can simultaneously enrich both LLMs and KGs is important.
Using this Colab Notebook, you can extract entity attributes from a list of URLs – even from pages embedded in JavaScript! In this implementation I used the LodgingBusiness schema (hotels, b&b and resorts).
Several lessons were learned from this study:
- We can seamlessly extract data from web pages using LLMs.
- It is advisable to continue using existing scraping techniques where possible. For example, BeautifulSoup is great for titles and meta descriptions.
- Using LLMs is slow and expensive, so optimizing the process is key.
- Once extracted, it is critical to thoroughly check and validate the data to ensure its accuracy and reliability. Data integrity is paramount!
The code is open to modification and adaptation according to your needs and can be integrated Autoscraper presented in this article.
Developed by Alireza Mika, it makes your web scraping fast, easy and fun. All credit goes to him for bringing innovation to a sector that isn’t evolving as fast as you might think.

If you’re interested in using the library in Python, I recommend reading Ali’s blog post on Medium.
I found this tool very powerful but limited to only a few use cases and decided to build one A simple Streamlit web application which you can use immediately.
Go to the web app here 🎈
Here’s how the scraping app works
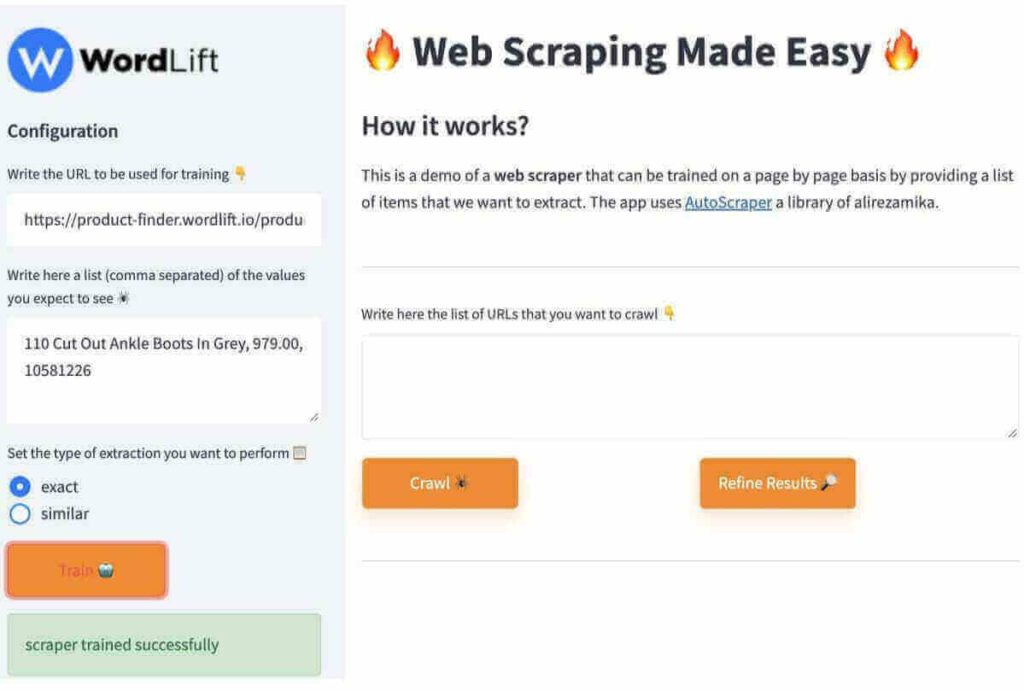
- You specify the URL of the web page to be used as a template. I’m using the product page on our eCommerce demo site as a reference.
- You add a list (comma separated) of the information you expect to be removed from this page. Here you can add anything, a text fragment, an image URL or a structured data property present in the markup. I add title, price and SKU in this example.
- You finally press “train” and let AutoScraper Let’s learn Remove these attributes from similar pages.
You can choose to run AutoScraper with the assumption that all pages will be the same (choose “exact”) or that they will have a similar structure (choose “similar“instead).
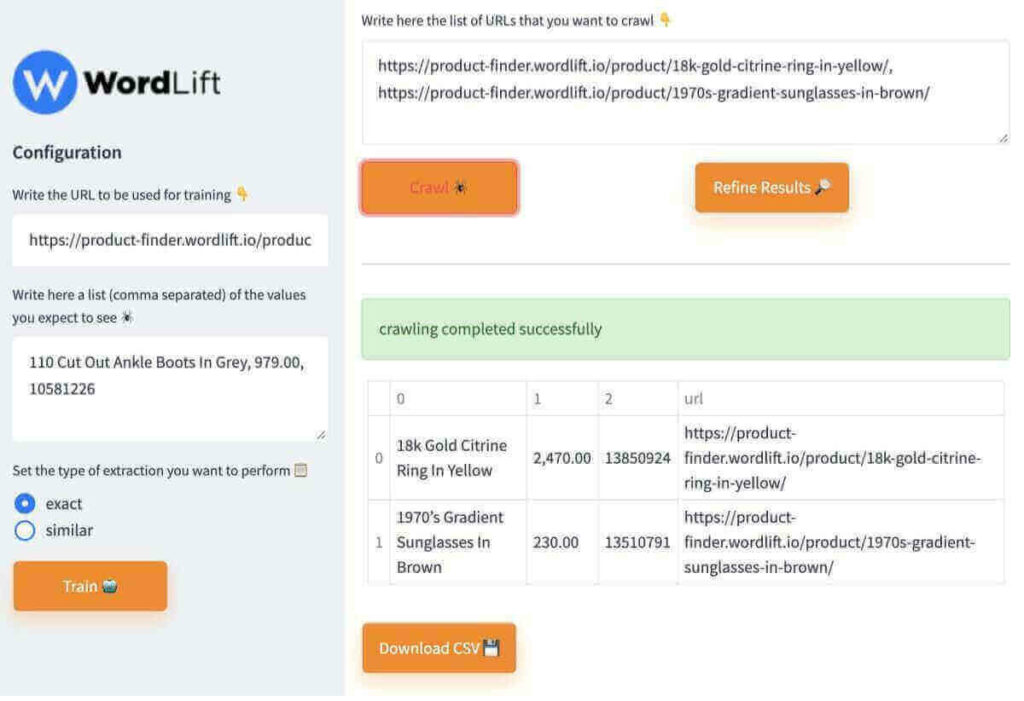
- Now you can add a list of pages you want to scrape. I have added two samples here. Note that there is a limit to the total number of characters you can add (and thus the total number of URLs you can strip). This is a demonstration tool and is only applicable to a limited set of pages.
- Voilà the job is done and now you can Download the CSV which contains the price, SKU and product name for each URL.
How to improve results
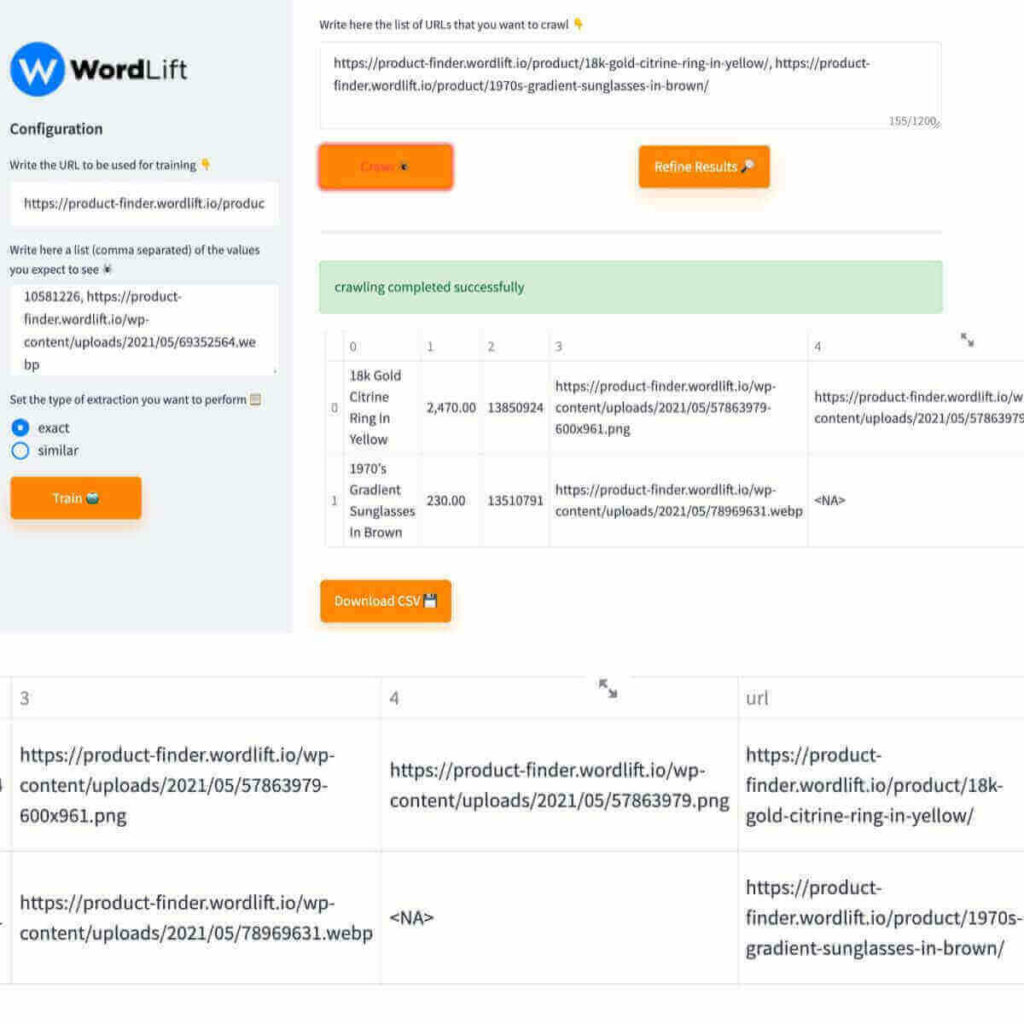
In some cases we may get false positives; In other words, AutoScraper may scrape data that we don’t need. In this case, we need to check the set of established rules and keep only what we need. Let’s review an example.
- If we add the image URL behind the reference product to the list of attributes we want to remove, we get a table with an unnecessary column (Column 4).
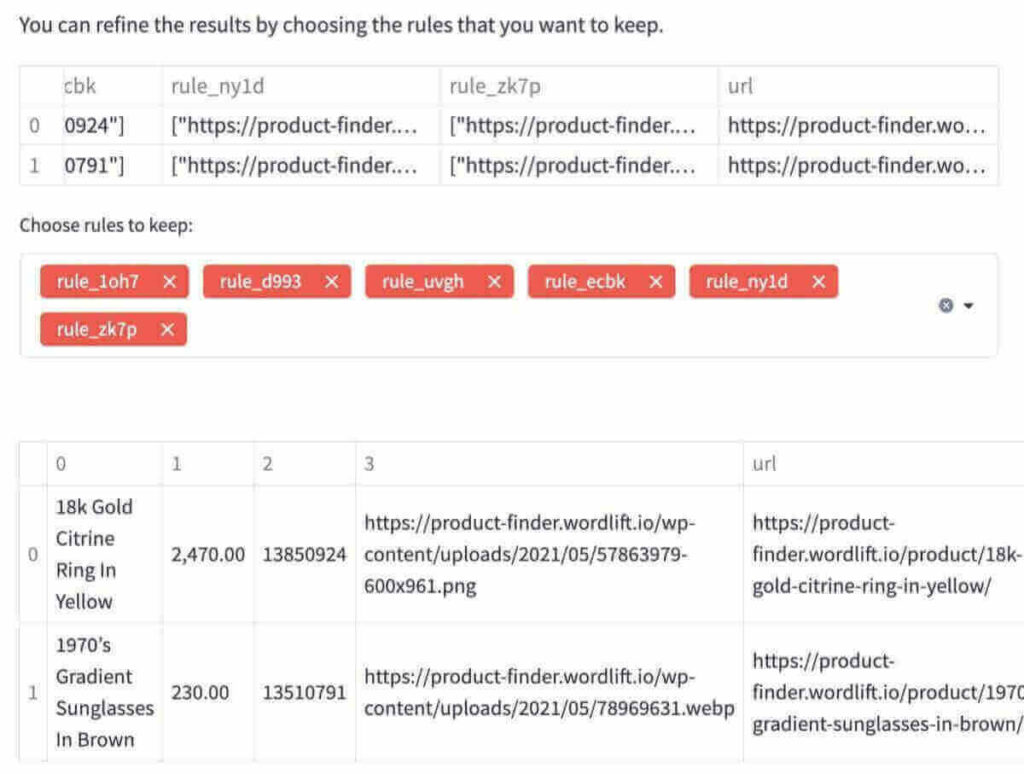
- We can now refine the rules by clicking the Refine Results button. Here we can see that if we remove rule_zk7p And press “Crawl” again, we have the correct table without the 4th column.
Existing restrictions
This is Demo web application. The interface is a bit clunky when you start tweaking the rules, and it’s generally limited to crawling. Just a few URLs. If you are looking for something that scales, I recommend it advertising tools, A famous Python library developed by Mithos Elias Dabas.
If you want to see how you can use it, watch this webinar. Elias Dabas and Doreid Haddad are shown here How to build a knowledge graph using Advertools and WordLift.
Is web scraping illegal?
No, web scraping is generally legal, which is why commercial search engines exist. However, there are a few considerations to keep in mind:
- Some websites may have terms and conditions that do not allow scraping;
- Technically speaking, scraping is a task that consumes a significant amount of bandwidth and computing resources. We will only do this when necessary. Google itself is reviewing its indexing policy to be more environmentally friendly; We should do it too.
- How we use the extracted data makes a big difference. We want to be respectful of other people’s content and aware of potential copyright violations.
You can find more useful information on this topic here.
How do we get the information?
Here’s a thread for you:
[ad_2]
Source link