
[ad_1]

Image by author (generated by Stable Diffusion 2.1)
Recently, Large Language Models or LLMs have dominated the world. With the introduction of ChatGPT, everyone could now benefit from the text generation model. But many powerful models are only available commercially, leaving a lot of research and customization.
Of course, there are many projects now trying to fully open up many LLM studies. Projects like Pythia, Dolly, DLite and many more are some examples. But why try to open LLMs? It is the community spirit that has driven all these projects to overcome the limitations that a closed model brings. However, do open source models compare to closed ones? Of course no. Many models can compete with commercial models and show promising results in many areas.
To continue this movement, one open source project to democratize LLM is RedPajama. What is this project and how will it benefit the community? Let’s explore this further.
RedPajama is a collaborative project between Ontocord.ai, ETH DS3Lab, Stanford CRFM and Hazy Research to create reproducible open source LLMs. The RedPajama project includes three stages, including:
- Pre-training data
- Base models
- Instruction tuning data and models
When this article was written, the RedPajama project had developed preliminary training data and models, including basic, instructional, and chat versions.
RedPajama pre-prepared data
In the first step, RedPajama tries to replicate the semi-open model LLaMa dataset. This means that RedPajama is trying to create pre-trained data with 1.2 trillion tokens and fully open source it to the public. Currently, full data and sample data can be downloaded at HuggingFace.
The data sources for the RedPajama dataset are summarized in the table below.
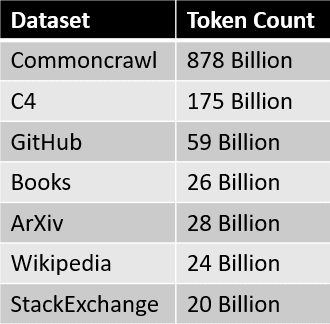
Where each piece of data is pre-processed and carefully filtered, the number of tokens also roughly matches the number reported in the LLaMa paper.
After creating the data set, the next step is to develop the base models.
Red pajama models
In the weeks following the creation of the RedPajama dataset, the first model trained on the dataset was released. Base models have two versions: 3 billion and 7 billion parameter models. The RedPajama project also releases two variations of each base model: custom and chat models.
A summary of each model can be found in the table below.

Image by author (adapted from .xyz)
You can access the models above using the following links:
Let’s try the RedPajama Base model. For example, we’ll try the RedPajama 3B base model with code adapted from HuggingFace.
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
# init
tokenizer = AutoTokenizer.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1"
)
model = AutoModelForCausalLM.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1", torch_dtype=torch.bfloat16
)
# infer
prompt = "Mother Teresa is"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
input_length = inputs.input_ids.shape[1]
outputs = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.7,
top_k=50,
return_dict_in_generate=True
)
token = outputs.sequences[0, input_length:]
output_str = tokenizer.decode(token)
print(output_str)a Catholic saint and is known for her work with the poor and dying in Calcutta, India.
Born in Skopje, Macedonia, in 1910, she was the youngest of thirteen children. Her parents died when she was only eight years old, and she was raised by her older brother, who was a priest.
In 1928, she entered the Order of the Sisters of Loreto in Ireland. She became a teacher and then a nun, and she devoted herself to caring for the poor and sick.
She was known for her work with the poor and dying in Calcutta, India.The result of the 3B Base model is promising and may be better if we use the 7B Base model. As development is still ongoing, the project may have an even better model in the future.
Generative AI is growing, but unfortunately many great models are still locked away in company archives. RedPajama is one of the leading projects trying to replicate the semi-open LLaMA model to democratize LLMs. By developing a dataset similar to LLama, RedPajama manages to create an open source 1.2 trillion token dataset that has been used by many open source projects.
RedPajama also distributes two kinds of models; 3B and 7B parameter base models, where each base model includes custom and chat models with instructions.
Cornelius Judah Vijaya is an Assistant Data Science Manager and Data Writer. While working full-time at Allianz Indonesia, he enjoys sharing Python and data tips through social media and writing media.
[ad_2]
Source link