
[ad_1]
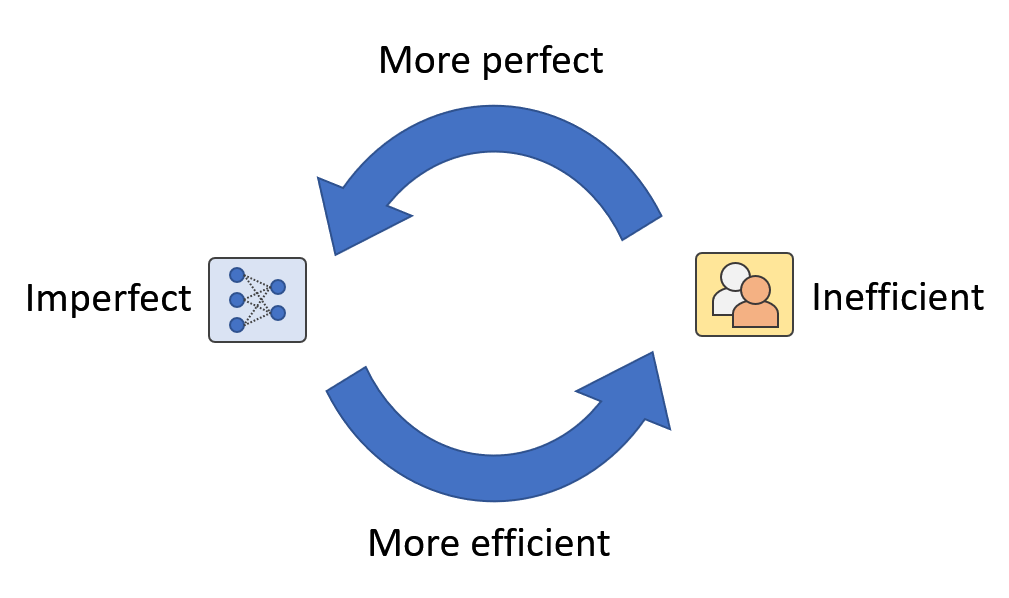
Figure 1: In real-world applications, we think of a human-machine loop where humans and machines reinforce each other. We call it Artificial Augmented Intelligence.
How to build and evaluate an AI system for real-world applications? In most AI research, the evaluation of AI methods involves a training-validation-testing process. Experiments usually stop when the models have good test performance on the reported data sets, because the real-world data distribution is likely to be modeled by the validation and test data. However, real-world applications are typically more complex than a single training-validation-testing process. The biggest difference is the ever-changing data. For example, wildlife datasets are constantly changing in class composition due to animal invasions, re-introductions, re-colonization, and seasonal movement of animals. A model that has been trained, validated and tested on existing data sets can easily be broken when newly collected data contain new species. Fortunately, we have propagation-free detection methods that can help us discover new species samples. However, when we want to extend the recognition capabilities (ie, the ability to recognize new species in the future), the best we can do is refine the models with new true annotations. In other words, we need to incorporate human effort/annotations regardless of how the models perform on previous test sets.
When human annotations are inevitable, real-world recognition systems become an infinite loop. Data collection → Annotation → Model specification (Figure 2). As a result, performing one step of model evaluation does not represent a true generalization of the entire recognition system, as the model is updated with new data annotations and a new round of evaluation is performed. Given this loop, we think that instead of building a model Better testing performancefocus How much human effort can be saved A more general and practical purpose in the real world.
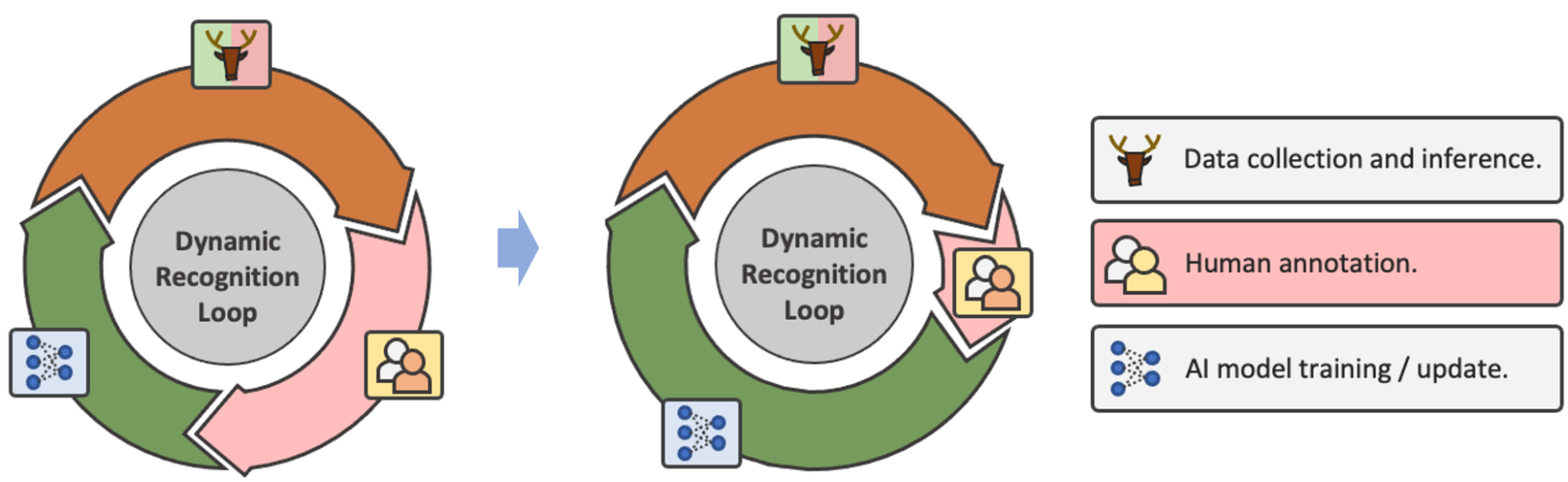
Figure 2: In the loop of data collection, annotation, and model updating, the goal of optimization becomes minimizing the need for human annotation rather than performing single-step recognition.
In a paper we published last year in Nature-Machine Intelligence [1], we discussed the inclusion of the human loop in wildlife detection and suggested testing the effectiveness of human effort in model updates instead of performing simple testing. To demonstrate, we built a recognition framework that was a combination of active learning, semi-supervised learning, and a human loop (Figure 3). We also included a time component in this framework to indicate that the recognition models were not stopped at any time step. In general, in the framework, at each step when new data is collected, the recognition model actively chooses which data to annotate based on a prediction confidence metric. Low-confidence predictions are sent for human annotation, while high-confidence predictions are trusted for downstream tasks or pseudo-labeling model updates.
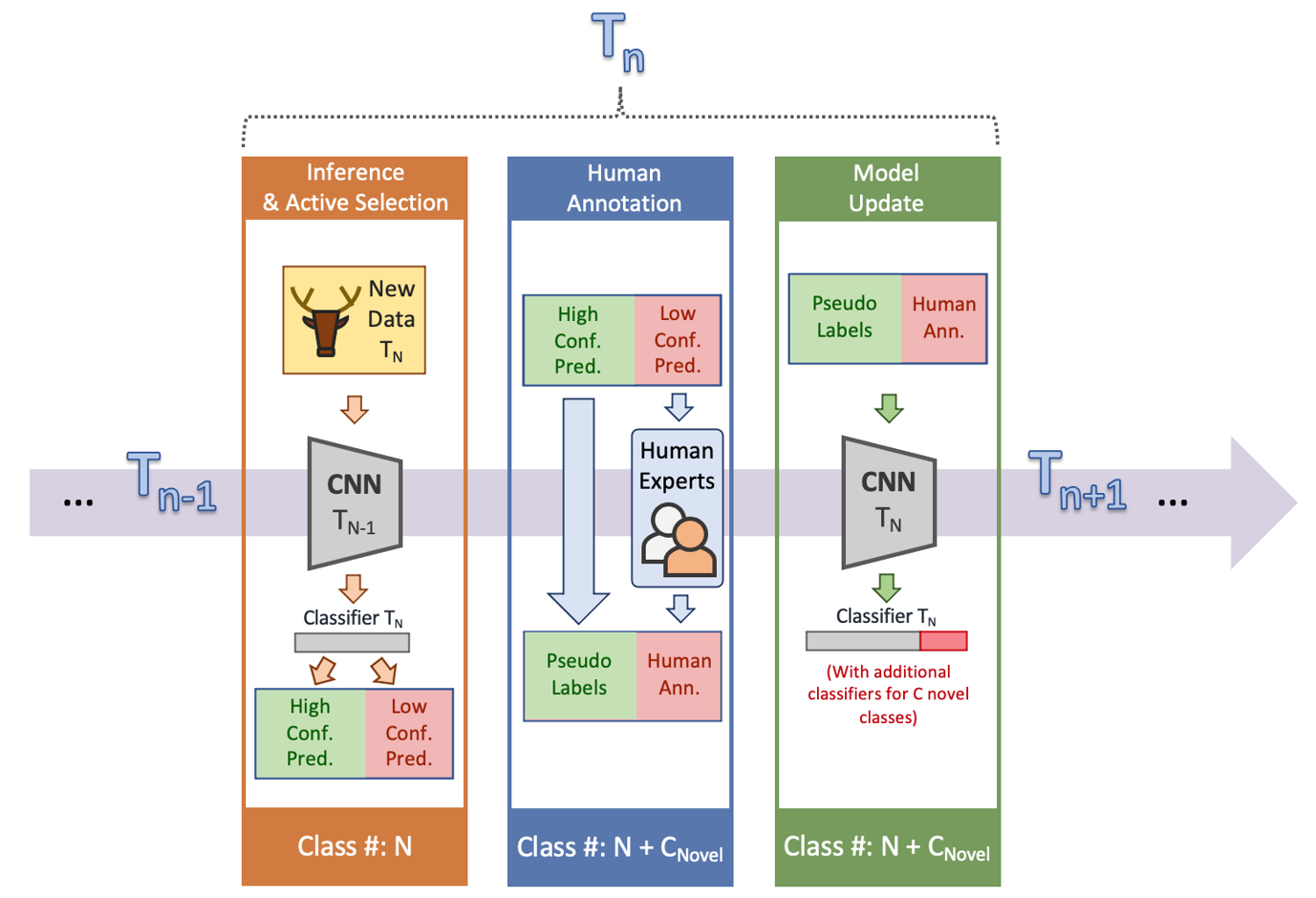
Figure 3: Here we present an iterative recognition framework that can maximize the use of state-of-the-art image recognition methods and minimize reliance on manual annotations for model updates.
In terms of the efficiency of human annotation for model updating, we divided the evaluation into 1) the percentage of high-confidence predictions during validation (ie, saved human annotation effort); 2) accuracy of highly reliable forecasts (ie reliability); and 3) the percentage of novel categories identified as low confidence predictors (ie, sensitivity to novelty). Through these three metrics, the framework is optimized to minimize human effort (ie, maximize high confidence percentage) and maximize model update efficiency and high confidence accuracy.
We report a two-stage experiment on a large-scale wildlife camera trap collected from a national park in Mozambique for demonstration purposes. The first step was an initialization step to initialize the model with only part of the data set. In the second step, a new data set with known and new classes was applied to the initialized model. After the framework, the model confidently made predictions on the new dataset, where high-confidence predictions were trusted as pseudo-labels, and low-confidence predictions were provided by human annotations. Then, the model was updated with both pseudo-labels and annotations and was ready for future time steps. As a result, the percentage of high-confidence predictions in the second-step validation was 72.2%, the accuracy of high-confidence predictions was 90.2%, and the percentage of new classes detected with low confidence was 82.6%. In other words, our framework saved 72% of the human effort in the second step to annotate all the data. As long as the model was confident, 90% of the predictions were correct. In addition, 82% of new samples were successfully detected. Details of the framework and experiments can be found in the original paper.
By looking at Figure 3 in more detail, in addition Data Collection – Human Annotation – Model Update loop, there is one more man-machine A loop hidden in the frame (Figure 1). It’s a loop where humans and machines constantly improve each other through model updates and human intervention. For example, when AI models are unable to recognize new classes, human intervention can provide information to expand the model’s recognition capabilities. On the other hand, as AI models become more and more general, the demand for human effort decreases. In other words, the use of human effort becomes more efficient.
In addition, our proposed trust-based Human Loop framework is not limited to new class detection, but can also help with issues such as long-range distribution and multi-domain inconsistencies. While AI models feel less confident, human intervention comes in to improve the model. Likewise, human effort is saved as long as AI models feel confident and sometimes human errors can even be corrected (Figure 4). In this case, the relationship between people and machines becomes synergistic. Thus, the goal of AI development is changing from replacing human intelligence to mutually reinforcing both human and machine intelligence. We call this type of AI: Artificial Enhanced Intelligence (A2).
Ever since we started working on artificial intelligence, we’ve been asking ourselves, what are we building AI for? Initially, we believed that ideally, artificial intelligence should completely replace human effort in simple and tedious tasks such as large-scale image recognition and driving a car. Thus, we have long been pushing our models to an idea called “human-level performance.” However, this goal of replacing human effort essentially establishes an opposition or mutually exclusive relationship between humans and machines. In real-world applications, the performance of AI methods is limited by many impact factors such as long-range distribution, multi-domain mismatch, label noise, weak supervision, out-of-distribution detection, etc. somehow be released by proper human intervention. The framework we propose is just one example of how these separate problems can be summarized into high- and low-confidence prediction problems and how human effort can be incorporated into an AI system. We think this is not cheating or succumbing to hard problems. This is a more human-centric way of developing AI, where the focus is on how much human effort is saved, rather than how many test images the model can recognize. Before the realization of Artificial General Intelligence (AGI), we think it is worth further studying the direction of human-machine interaction, etc.2I want artificial intelligence to make a greater impact in a variety of practical areas.

Figure 4: Examples of high confidence predictions that did not match the original annotations. Many high-confidence predictions that were flagged as incorrect based on validation labels (provided by students and citizen scientists) were in fact correct upon closer inspection by wildlife experts.
Acknowledgments: We thank all co-authors of the paper “Automatic Identification of Repetitive Human and Wildlife Images” for their contributions and discussions in the preparation of this blog. The views and opinions expressed in this blog are solely those of the authors of this paper.
This blog post is based on the following paper published in Nature – Machine Intelligence:
[1] Miao, Zhong, Ziwei Liu, Caitlin M. Gaynor, Meredith S. Palmer, Stella X. Yu, and Wayne M. getz “Iterative Human and Automatic Identification of Wildlife Images.” Nature Machine Intelligence 3, no. 10 (2021): 885-895. (link to pre-print)
[ad_2]
Source link