
[ad_1]
The pandemic has forced most people indoors. Along with that, there has been a corresponding rise in online education companies offering courses to help you upgrade your skills. Most of them follow the so-called “freemium” model, where you can watch the course videos and do the exercises, but if you want certification or support, you have to pay. In the past, I’ve aggressively taken advantage of these freebies and learned a lot in the process, so I’m very grateful for the freemium model and hope it continues, but nowadays I feel more selective than I used to. However, I recently came across a very interesting product offered by Manning.com – a “living project” about detecting disease outbreaks from news headlines, which promises a hands-on user exposure to extracting text from pandas, Scikit-Learn. , KMeans and DBScan clustering as done by the project.
Although, in fairness, the idea is somewhat rare, it is not entirely new. Kaggle was there first, with starter datasets and machine learning projects. However, there is one important difference – the Manning liveProject is divided into steps, each of which has high-level instructions on the prescribed approach to solve that step, but supplemented with educational material extracted from one of Manning’s books. I thought it was a really cool idea to reuse existing content and potentially open it up to a different demographic. In this sense, it reminds me of the Google Places API, which was created by combining the maps provided by Google Maps and the location feedback from users who use it.
In any case, the sort of project is to find outbreaks of one or more diseases from newspaper headlines collected over a period of time and plot them on a map to discover clusters. If a cluster occurs in several geographic areas, it may be classified as a pandemic. I signed up mainly because (a) most of the clustering I’ve done so far involves topics and terms in text, so geographic clustering seemed new and cool to me, and (b) my son is an aspiring data scientist, and I figured maybe we could pair-program and do it together Let’s learn. However, the project turned out to be quite interesting and I stuck with it, and ended up optimizing for (a) more than (b). Then :-).
I put together a project template provided by one of the instructors and implemented the project steps as Jupyter notebooks and finally wrote my project report (a mandatory deliverable for liveProject) as a README.md file for my fork. The steps are listed in the methods section. At a high level, the transition from a list of newspaper headlines to disease clusters on a map (world and US) involved the following steps:
The project offers about 650 news headlines taken from various news agencies at an unspecified time, so it reflects the state of the world for some snapshots. We specify the country and city in the headers using a regular expression. Specifically, we construct regexes from the list of countries and cities in the GeoNamesCache library and run them against the titles, specifying the names of the cities and countries found in each title. Of the 650 titles, 634 could be fully resolved by both country and city names, 1 by the country name only, and 15 for which neither country nor city could be found. The resolved city and country names are used to find the latitude and longitude coordinates of each of the 634 cities, again using the GeoNamesCache. Other titles were removed from further analysis.
The coordinates of the cities are then plotted on a world map (Figure 1) and it appears that there are outbreaks of the disease everywhere during this time. Note that the project additionally asks specifically for the United States, but to keep the blog post short, we won’t talk about that here. But you can find this visualization in notebooks.
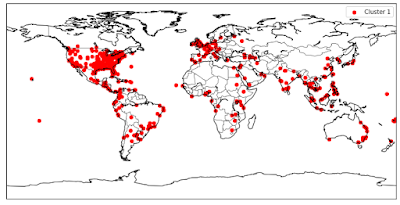
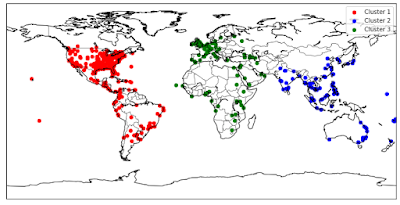
Clustering them using the K-Means algorithm helps somewhat, but mostly clusters points by latitude – the first cluster is the Americas, the second is Europe, Africa and West Asia, and the third is South Asia and Australia.
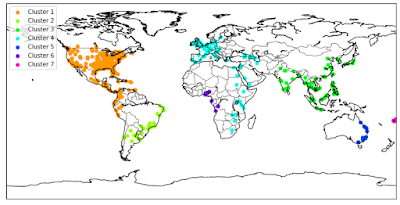
Heading clustering, the density-based method DBSCAN produces finer-grained clusters.
The distance measure used in the cluster above was the standard Euclidean distance, which is more suitable for a flat earth. A better distance measure for a spherical Earth would be the great circle distance. Using this distance measure and DBSCAN’s standard hyperparameters, we get a cluster that is even finer-grained.
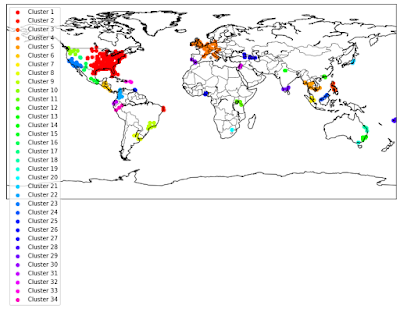
At this point, most of the United States and Western Europe seem to be suffering from one major disease or another. Given that the imaging clearly indicated disease clusters, we wanted to know if these were all the same disease or different diseases. We then extracted and manually scanned the “most representative” newspaper headlines (ie, headlines that had coordinates with the centers of each cluster), looking for easily identifiable diseases, then looking at adjacent words, then using these words To find more diseases. Using this strategy, we were able to count the number of titles for each disease. It turned out that although they talked about different diseases, the dominant one was the Zika virus.
So we filtered the newspaper headlines for Zika virus (about 200 of them) and combined them using their latitude and longitude using DBSCAN and great circle distance and got this.
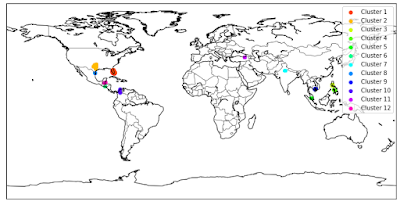
Based on this visualization, we can see that the largest outbreak appears to be in the central part of the Americas, with two large clusters in the southern United States, Mexico, and Ecuador in South America. There is also a significant cluster in Southeast Asia and one in northern India, and smaller outbreaks in western Asia. Since our supposed client is the World Health Organization (WHO), we have to make a recommendation, and the recommendation is that it is a pandemic, since the outbreak is in many countries.
It was a fun exercise and I learned about map-based clustering and visualization, which was relatively new to me as I had never used it before. I think the liveProject idea is very strong and has a lot of potential. If you’re interested in the code, the notebooks are here.
[ad_2]
Source link