
[ad_1]
A while back, Quora posted a “Keras vs. Pytorch” question that I decided to ignore because it seemed like too much playbait. A few weeks ago, after discussions with colleagues and (professional) acquaintances who had tried libraries like Catalyst, Ignite and Lightning, I decided to also get on the Pytorch boilerplate elimination train and try Pytorch Lightning. As I did so, my thoughts inevitably returned to the Quora question, and I came to the conclusion that, in their current form, the two libraries and their respective ecosystems are more similar than different, and that there is no technological reason. Choosing one over the other. Let me explain.
Neural networks are trained using gradient descent. The central idea of gradient descent can be nicely captured in the equation below (taken from the same related gradient descent article) and referred to as the “training cycle”. Of course, there are other aspects of neural networks, such as model and data definition, but it is the learning cycle where the differences in the earlier versions of the two libraries and their subsequent integration are most apparent. Therefore, I will mainly talk about the training cycle here.
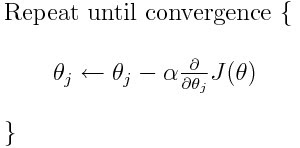
Keras was originally conceived as a high-level API on top of the low-level graph-based APIs from Theano and Tensorflow. Graph APIs allow the user to first define a computational graph and then execute it. After defining the graph, the library will try to create the most efficient representation of the graph before execution. This makes execution more efficient, but adds a lot of boilerplate to the code and makes it harder to debug if things go wrong. The biggest success of Keras, in my opinion, is its ability to hide the graph API almost entirely behind an elegant API. In particular, his “training loop” looks like this:
model.compile(optimizer=optimizer, loss=loss_fn, metrics=[train_acc])
model.fit(Xtrain, ytrain, epochs=epochs, batch_size=batch_size)
|
Of course, the adjust method has many other parameters, but the most difficult one is the one line call. And perhaps this is all that is needed for simple cases. However, as networks get a bit more complex, perhaps with multiple models or loss functions, or custom update rules, the only option for Keras was to drop TensorFlow or Theano code. In these situations, Pytorch looks really attractive, with its learning loop power, simplicity, and readability.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
dataloader = DataLoader(Xtrain, batch_size=batch_size)
for epoch in epochs:
for batch in dataloader:
X, y = batch
logits = model(X)
loss = loss_fn(logits, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# aggregate metrics
train_acc(logits, loss)
# evaluate validation loss, etc.
|
However, with the release of Tensorflow 2.x, which included Keras as a default API via the tf.keras package, it is now possible to do something identical with both Keras and Tensorflow.
1 2 3 4 5 6 7 8 9 10 11 12 |
dataset = Dataset.from_tensor_slices(Xtrain).batch(batch_size)
for epoch in epochs:
for batch in dataset:
X, y = batch
with tf.GradientTape as tape:
logits = model(X)
loss = loss_fn(y_pred=logits, y_true=y)
grads = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
# aggregate metrics
train_acc(logits, y)
|
In both cases, developers agree to deal with a certain amount of boilerplate in exchange for additional power and flexibility. The approach taken by each of the three Pytorch add-on libraries I listed earlier, including Pytorch Lightning, is to create a Trainer object. The trainer constructs the training loop as an event loop with hooks into which specific functions can be injected as callbacks. The functionality of this callback will be executed at specific points in the learning loop. So a partial LightningModule subclass for our use case would look like this, see the Pytorch Lightning Documentation or my code examples below for more details.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
class MyLightningModel(pl.LightningModule):
def __init__(self, args):
# same as Pytorch nn.Module subclass __init__()
def forward(self, x):
# same as Pytorch nn.Module subclass forward()
def training_step(self, batch, batch_idx):
x, y = batch
logits = self.forward(x)
loss = loss_fn(logits, y)
acc = self.train_acc(logits, y)
return loss
def configure_optimizers(self):
return self.optimizer
model = MyLightningModel()
trainer = pl.Trainer(gpus=1)
trainer.fit(model, dataloader)
|
If you think about it, the event looping strategy used by Lightning’s trainer.fit() is exactly how Keras’ training loop manages to transform itself into a one-line model.fit() call, with many of its parameters acting as callbacks. Monitor exercise behavior. Pytorch Lightning is a bit clearer (and well, a bit more extensive) about this. In fact, both libraries have solutions that address the other’s pain points, so the only reason you’d choose one or the other is personal or corporate preference.
In addition to the calls for each training, validation, and testing step, there are additional calls for each of these steps that are called at the end of each step and epoch, for example: training_epoch_end() and training_step_end(). Another nice side effect of getting something like Pytorch Lightning is that you get the default event loop functionality for free. For example, logging is done on Tensorboard by default and progress bars are controlled using TQDM. Finally, (and this is the raison d’être of Pytorch Lightning from the perspective of its developers) it helps you organize your Pytorch code.
To introduce Pytorch Lightning, I took three of my old notebooks, each dealing with one basic type of neural network architecture training (from the old days) – fully connected, convolutional, and recurrent networks, and converted them to use Pytorch. Lightning. In addition, you may find the extensive Pytorch Lightning documentation, including the links below, useful.
[ad_2]
Source link