
[ad_1]
Google’s AI for Social Good team is made up of researchers, engineers, volunteers and others with a shared focus on positive social impact. Our mission is to demonstrate the social benefits of AI by incorporating real-world value, with projects that include work in public health, affordability, crisis response, climate and energy, nature and society. We believe the best way to effect positive change in underserved communities is to partner with change makers and the organizations they serve.
In this blog post, we discuss the work done by Project Euphonia, an AI social good group that aims to improve automatic speech recognition (ASR) for people with speech disorders. For people with typical speech, the word error ratio (WER) of an ASR model can be less than 10%. But for people with speech disorders such as stuttering, dysarthria, and apraxia, the WER can reach 50% or even 90% depending on etiology and severity. To address this issue, we worked with over 1,000 participants to collect over 1,000 hours of disordered speech samples and used the data to show that ASR personalization is an effective way to bridge the performance gap for users with disordered speech. We have shown that personalization can be successful with 3-4 minutes of practice speech using layer freezing techniques.
This work led to the development of Project Relate for people with atypical speech who could benefit from a personalized speech model. Created in partnership with Google’s speech team, Project Relate allows people who have trouble understanding other people and technology to build their own models. People can use these personalized models to communicate more effectively and gain more independence. To make ASR more accessible and usable, we describe how we refined Google’s Universal Speech Model (USM) to better understand disordered speech, without personalization, for use with digital assistant technologies, dictation apps, and conversations.
Solving the challenges
Working closely with Project Relate users, it became clear that custom models can be very useful, but for many users, recording tens or hundreds of examples can be difficult. Furthermore, personalized models did not always perform well in free speech.
To address these challenges, Euphonia’s research efforts have been focused independent speaker ASR (SI-ASR) to make models work better for people with speech impairments so that no additional training is required.
Requested Speech Dataset for SI-ASR
The first step in building a robust SI-ASR model was to create a representative partition of the data. We created the requested speech dataset by partitioning the Euphonia corpus into training, validation, and test partitions, while ensuring that each partition covered a range of speech impairment severity and underlying etiology, and that no speakers or phrases appeared with multiple partitions. The training part consists of more than 950 thousand speech utterances from more than 1000 speakers with impaired speech. The test set contains approximately 5,700 utterances from over 350 speakers. Speech pathologists manually reviewed all utterances in the test set for transcription accuracy and audio quality.
Real Speaking Test Kit
Unsolicited or conversational speech differs from solicited speech in several ways. In conversation, people speak faster and express less. They repeat words, correct mispronounced words, and use a larger vocabulary that is specific and personal to them and their community. To improve the model for this use case, we created a real conversational test suite that functions as a benchmark.
The real conversation test suite was created with the help of trusted testers who recorded themselves speaking. The audio was reviewed, any personally identifiable information (PII) removed, and this data was then transcribed by a speech-language pathologist. The real speech test set contains more than 1500 utterances from 29 speakers.
Adaptation of USM to disordered speech
We then applied USM to the training portion of the Euphonia Prompted Speech suite to improve its performance on disordered speech. Instead of refining the full model, our setup was based on residual adapters, a parameter-efficient tuning approach that adds tunable bottleneck layers as residuals between transformer layers. Only these layers are adjusted, and the rest of the model’s weight is intact. We have previously shown that this approach works very well for adapting ASR models to disordered speech. Residual converters were added to the encoder layers only and the bottle dimension was set to 64.
results
To evaluate the adapted USM, we compared it to the old ASR models using the two test sets described above. For each test, we compare the adapted USM with the pre-USM model best suited for the task: (1) for short-demanded speech, we compare the Google-produced ASR model optimized for short-form ASR; (2) For longer real conversational speech, we compare a model trained for long-form ASR. The improvement of USM over pre-USM models can be explained by the increase in relative size of USM, from 120M to 2B parameters, and other improvements discussed in the USM blog post.
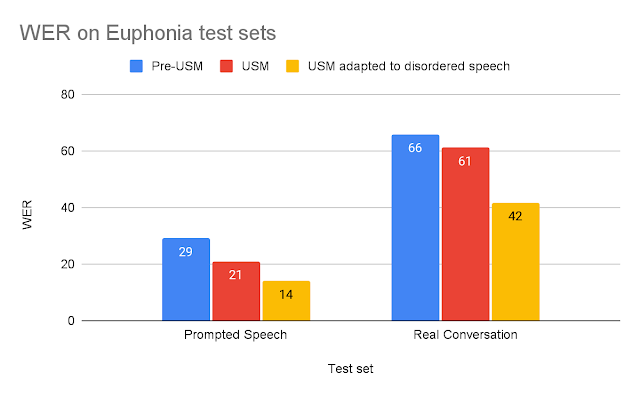 |
| Model word error ratios (WER) for each test set (lower is better). |
We can see that USM adapted to disordered speech significantly outperforms other models. The WER of the adapted USM on real speech is 37% better than the pre-USM model, and on the Prompted Speech test set, the adapted USM performs 53% better.
These findings suggest that adapted USM is significantly more usable for end users with disordered speech. We can demonstrate this improvement by looking at real-talk test set recordings from a trusted Euphonia and Project Relate tester (see below).
| Audio1 | The real truth | Pre-USM ASR | Adapted from USM | |||
| I now have an Xbox Adaptive Controller on my lap. | I have it now Many and that consultant about me person | I now Had xbox adapter Controller on me lamp. | ||||
| I’ve been talking for quite some time now. Let’s see. | It’s been quite a while | I’ve been talking for quite some time now. |
| An example of a trusted tester’s speech audio and transcriptions from a real-talk test set. |
Comparing pre-USM and adapted USM transcripts revealed several key advantages:
-
The first example shows that the adaptive USM can better recognize disordered speech patterns. The baseline is missing keywords like “XBox” and “controller” that are important for the listener to understand what he’s trying to say.
-
The second example is a good example of how deletion is a major problem in ASR models that are not trained on disordered speech. Although the baseline model correctly transcribed part of the utterance, much of the utterance was not transcribed, thereby losing the speaker’s intended message.
conclusion
We believe this work is an important step towards making speech recognition more accessible to people with speech disorders. We continue to work on improving the performance of our models. With the rapid advancements of ASR, we aim to ensure the benefits of people with speech disorders as well.
Acknowledgments
Key contributors to this project include: Fuddy Biads, Michael Brenner, Julie Catio, Richard Caivy, Amy Chung-Yu Chow, Dothan Emanuel, Jordan Green, Russ Haywood, Pan-Pan Jiang, Anton Cast, Marilyn Ladewig, Bob McDonald, Philip Nelson, Kathy Seaver, Joel Shore, Jimmy Tobin, Kathryn Tomanek and Subhashin Venugopalan. We gratefully acknowledge the support Project Euphonia received from members of the USM research team, including Yu Zhang, Wei Han, Nanxin Chen, and many others. Most importantly, we wanted to say a big thank you to the 2,200+ participants who recorded speech samples and the many advocacy groups who helped us connect with these participants.
1The audio volume has been adjusted for listening, but the original files will be more in line with the files used in the exercise and will have pauses, silence, variable volume, etc. ↩
[ad_2]
Source link