
[ad_1]
This post discusses my highlights from ACL 2021, including challenges in benchmarking, machine translation, model understanding, and multilingual NLP.

ACL 2021 was held practically on August 1-6, 2021. Here is my keynote:
NLP benchmarking is broken
Many reports and papers have addressed the current state of NLP benchmarking, whereby existing benchmarks are largely outperformed by rapidly improving pre-trained models.
My favorite resources from the conference on this topic are:
I also wrote a longer blog post that provides a broader overview of the various perspectives, challenges, and potential solutions for improving benchmarking in NLP.
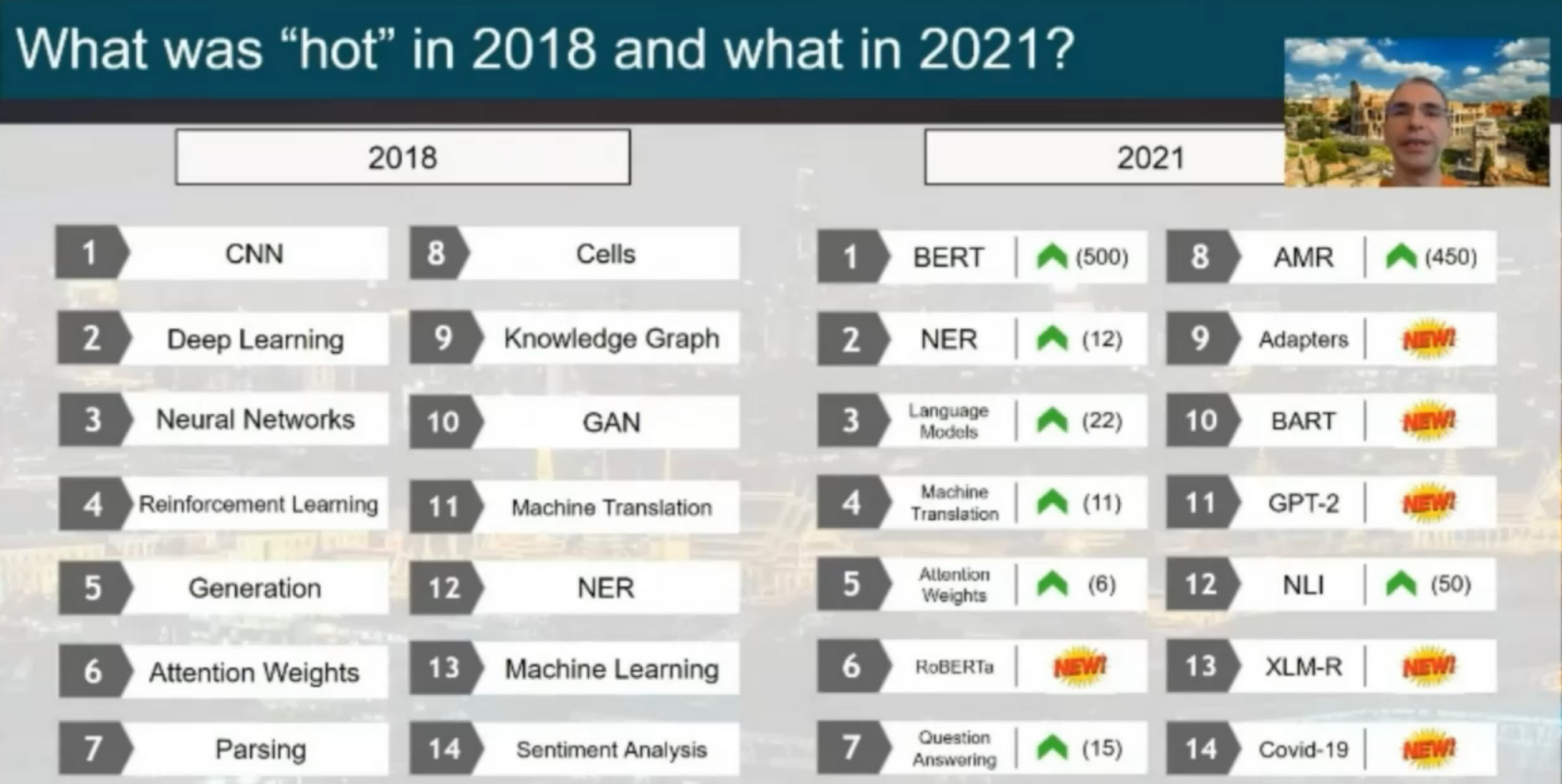
NLP is all about pre-made transformers
This shouldn’t come as a surprise, but it’s still interesting to see that among the 14 “hot” topics for 2021 (see below) were five pre-trained models (BERT, RoBERTa, BART, GPT-2, XLM-R) and one general. Topic “Language models”. These models are essentially all variants of the same transformer architecture.
It serves as a useful reminder that society over-fits a particular setting and that it might be worth looking beyond the standard transformer model (see my recent newsletter for inspiration).
There have been several papers that have attempted to improve the general transformer architecture for processing long and short documents:
Automatic translation
Machine Translation, as in past years, was one of the most popular tracks at the conference, trailing the general ML track in terms of the number of submissions, as seen below.
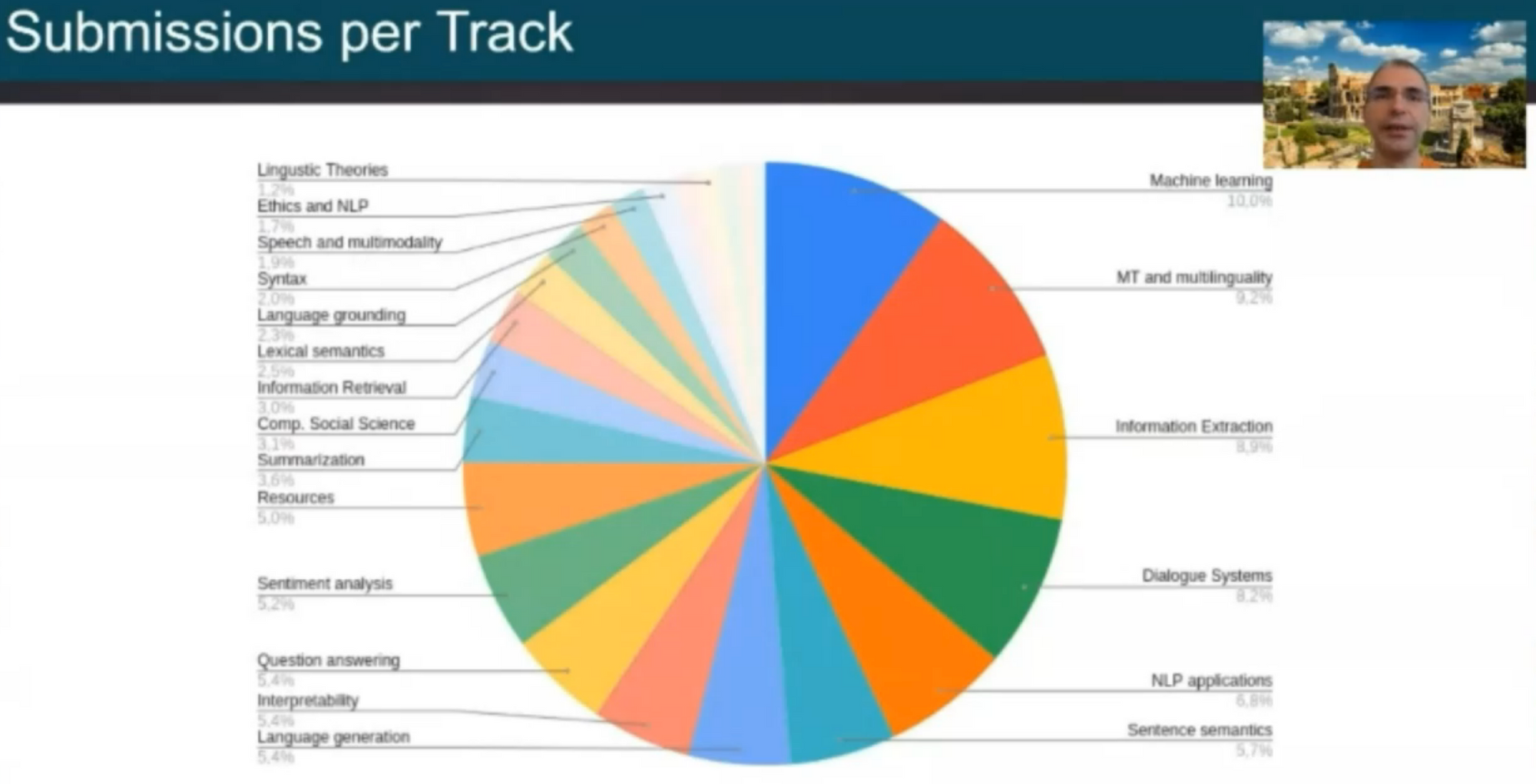
3 of the top 6 papers are on MT:
- Scientific credibility of machine translation research: A meta-evaluation of 769 papers. Mari et al. Investigate how reliable the assessment is across a large number of papers. They find that almost all papers used BLEU; 74.3% exclusively used BLEU. In the last decade, 108 new MT metrics have been proposed, but none have been used consistently. Not surprisingly, most papers do not test for statistical significance. The copying of works from previous works is increasing. Sometimes scores are reported using different variants of the BLEU script and are therefore not comparable. They provide the following guidelines for MT evaluation: do not use BLEU exclusively, test for statistical significance, do not copy numbers from previous work, compare systems using the same preprocessed data. More recently, in 2022, Benjamin Marry wrote additional posts in which he analyzed the shortcomings of the MT evaluation of outstanding papers.
- Neural machine translation with monolingual translation memory. Kai et al. Combine neural networks with non-parametric memory.
- Vocabulary learning for neural machine translation via optimal transport. Xu et al. Framework vocabulary learning as an optimal transport. They suggest using marginal utility as a measure of good vocabulary.
Within machine translation, there were a few works that I particularly liked:
There have also been several papers focusing on machine translation for low-resource language varieties without using parallel data for those languages:
Understanding models
A better understanding of the behavior of current models was another theme of the conference, with three of the six outstanding papers in this area:
- The intrinsic dimension explains the effectiveness of language model refinement. This paper analyzes refinement through the lens of intrinsic dimensionality and shows that conventional pre-trained models have very low intrinsic dimensionality. They also show that pretraining indirectly reduces intrinsic dimensionality and that larger models have lower intrinsic dimensionality. Internal dimension is a very relevant concept for the evaluation and design of effective pre-trained models, which we discussed in the EMNP 2022 guide.
- Pay attention to your favorites! Examining the negative effects of exposure to active learning to answer visual questions. This paper investigates the failure of active learning on VQA. The authors observe that the acquired examples are collective exceptions, that is, groups of examples that are difficult or impossible for current models. Removing such complex exceptions makes active learning easier.
- Unnatural language inference. This paper changes the word order of NLI sentences to investigate whether the models are “syntax aware”. They find that the latest NLI models are largely invariant to changes in word order. They observe that some distribution information (POS neighborhood) may be useful for working well in a modified configuration. Not surprisingly, human annotations struggle with modified sentences.
I also liked the following two papers that developed new methods and frameworks for understanding model behavior:
Language transfer and multilingual NLP
In addition to machine translation, I enjoyed the following papers on language transfer and multilingual NLP:
Challenges in natural language generation
Natural language generation (NLG) is one of the most challenging parameters for NLP. Some of the papers I liked focused on some of the challenges of various NLG applications:
Virtual conference notes
Finally, I’d like to share a few short notes to add to the ongoing conversation around the virtual conferencing format. I was mostly looking forward to attending the poster sessions because that’s usually my main conference (besides the social). There were two in my time zone. Each poster session consisted of a large number of tracks being presented simultaneously, leaving significantly less time for discussion with poster presenters from other areas.
Finding specific posters was difficult because the virtual posters did not show the name of the poster and the authors. In addition, the space between the posters was too small to mix the audio between posters with large masses.
In the future I would really like to see poster sessions that:
- greater in number and covering only a few gauges;
- distributed throughout the day and time zones;
- Easy navigation and enough space between posters.
Two other things that would have improved my virtual conference experience were a) a chat system more seamlessly integrated into the conference platform and b) tighter integration between the conference platform and the ACL anthology (linking the papers in the anthology would be nice).
Attending Zoom sessions for paper presentations went well, and I enjoyed watching recordings of other talks and conferences.
[ad_2]
Source link