
[ad_1]
Some time ago, I was thinking about different data augmentation strategies for unbalanced data sets, i.e. data sets in which one or more classes are overrepresented compared to others, and wondered how these strategies stack up. So I decided to create a simple experiment to compare them. This post describes the experiment and its results.
The dataset I chose for this experiment was the SMS spam collection dataset from Kaggle, a collection of nearly 5,600 text messages consisting of 4,825 (87%) lions and 747 (13%) spam. The network is a simple 3-layer fully connected network (FCN) whose input is a 512-element vector generated using Google’s Universal Sentence Encoder (GUSE) against text and outputs a 2-element vector argmax (representing “ham” or “spam”). . The text augmentation strategies I considered in my experiment are as follows:
- basic — This is the baseline result for comparing results. Since the task is binary classification, we chose the metric is accuracy. We train the network for 10 epochs using Cross Entropy and AdamW Optimizer with a learning rate of 1e-3.
- class weight — Class weighting attempts to resolve data imbalances by assigning more weight to the minority class. Here we will assign class weights to our optimizer proportional to the inverse of their number in the training data.
- Lack of majority class selection — In this scenario, we sample the number of entries from the majority class into the minority class and use only a selected subset of the majority class plus the minority class for our training.
- Oversampling the minority class — This is the opposite scenario, where we select (with replacement) the number of records from the minority class that are equal to the number of the majority class. A sample set contains repetitions. Then we use the selected set plus the majority class for training.
- SMOTE — This is a variant of the previous strategy of oversampling the minority class. SMOTE (Synthetic Minority Oversampling TEchnique) provides more heterogeneity in the oversampled minority class by creating synthetic records by interpolating between real records. SMOTE requires vectorization of the input data.
- Text enhancement — Like the two previous approaches, this is another oversampling strategy. Heuristics and ontology are used to make changes to the input text that preserve its meaning as much as possible. I used TextAttack, a Python library to zoom in on text (and create examples of reverse attacks).
A few points should be noted here.
First, all selection methods, i.e., all the strategies listed above, except for baseline and class weights, require you to split your training data into training, validation, and test parts before they can be used. Also, sampling should only be done on the training split. Otherwise, you run the risk of data leakage, where extended data leaks into validation and splits into testing, giving you overly optimistic results during model development that don’t hold true when you move your model to production.
Second, augmenting your data using SMOTE can only be done on vectorized data, since the idea is to find and use points in the hyperspace of features that lie between your existing data. Because of this, I decided to pre-vectorize my text input using GUSE. Other amplification approaches discussed here do not require pre-vectorization of the input.
The code for this experiment is divided into two notebooks.
- blog_text_augment_01.ipynb — In this notebook I split the dataset into a 70/10/20 train/validation/test split and vector representations for each text message using GUSE. I also select the minority class (spam) by generating about 5 magnifications for each record and also create their vector representations.
- blog_text_augment_02.ipynb — I define a common network to retrain using Pytorch from the 6 augmentation scenarios listed above and compare their accuracy.
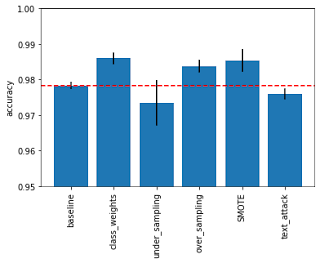
The results are shown below and seem to indicate that oversampling strategies perform best, both naive and based on SMOTE. The next best choice seems to be class weight. This seems understandable since oversampling gives the network the most data to train on. Perhaps it is also that the lack of selection does not work well. I was also a little surprised that the text augmentation strategies didn’t work as well as the other oversampling strategies.
 |
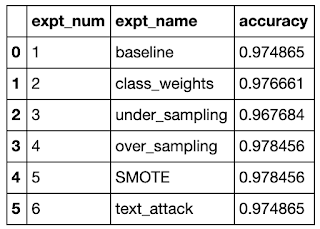 |
However, the differences here are quite small and perhaps not very significant (note that the y-axis in the bar graph is exaggerated (from 0.95 to 1.0) to emphasize this difference). I also found that the results varied across multiple runs, likely due to different initialization scenarios. But overall the pattern shown above was the most common.
Edit 2021-02-13: @Yorko suggested using confidence intervals to address my above concerns (see comments below), so I collected the results from 10 runs and calculated the mean and standard deviation for each approach for all runs. The updated bar chart above shows the mean value and has error bars of +/- 2 standard deviations from the mean result. Thanks to the error bars, we can now draw some additional conclusions. First, we can see that SMOTE under oversampling can indeed perform better than naive oversampling. It also shows that sampling results can be highly variable.
[ad_2]
Source link