
[ad_1]

Image from Adobe Firefly
I recently started an AI-focused educational newsletter that already has over 160,000 subscribers. TheSequence is an ML-focused newsletter that takes 5 minutes to read. The aim is to introduce you to machine learning projects, research papers and concepts. Please try it out by subscribing below:
Recent advances in large language models (LLM) have revolutionized the field, equipping them with new capabilities such as natural dialog, mathematical reasoning, and program synthesis. However, LLMs still have inherent limitations. Their ability to store information is limited by fixed weights, and their computational capabilities are limited to static graphs and narrow contexts. Furthermore, as the world evolves, LLMs need retraining to update their knowledge and reasoning abilities. To overcome these limitations, researchers have begun to augment LLMs with tools. By providing access to broad and dynamic knowledge bases and engaging complex computational tasks, LLMs can leverage search technologies, databases, and computational tools. Leading LLM providers have begun integrating plugins that allow LLMs to call external tools via APIs. This transition from a limited set of hand-coded tools to access to a vast array of cloud APIs has the potential to transform LLMs into a major interface to computing infrastructure and the Internet. Tasks like booking vacations or hosting conferences can be as simple as talking to LLM, which has access to flight, car rental, hotel, dining, and entertainment web APIs.
Recently, researchers at UC Berkeley and Microsoft introduced Gorilla, an LLaMA-7B model designed specifically for API calls. Gorilla relies on its own instruction specification and retrieval techniques to enable LLMs to accurately select from a large and evolving set of tools expressed through their APIs and documentation. The authors build a large corpus of APIs, called APIBench, by extracting machine learning APIs from major model hubs such as TorchHub, TensorHub, and HuggingFace. Using self-instructions, they create pairs of instructions and corresponding APIs. The refinement process involves converting the data into a user agent chat-style conversational format and performing standard instruction refinements on the base LLaMA-7B model.

Image credit: UC Berkeley
API calls often come with limitations that add complexity to understanding and categorizing LLM calls. For example, a query may require an image classification model to be invoked by limiting the size and accuracy of a particular parameter. These challenges highlight the need for LLMs to understand not only the functional description of API calls, but also the reason for the built-in limitations.
The technology-focused database includes three distinct domains: Torch Hub, Tensor Hub, and HuggingFace. Each domain contains a wealth of information that sheds light on the diverse nature of the dataset. For example, Torch Hub offers 95 APIs, providing a solid foundation. In comparison, Tensor Hub steps up with an extensive collection of 696 APIs. Finally, HuggingFace leads the pack with a whopping 925 APIs, making it the most comprehensive domain.
An additional effort was made to enhance the value and usability of the data set. Each dataset API is accompanied by 10 detailed and uniquely tailored instructions. These instructions are an indispensable guide for both training and evaluation purposes. This initiative ensures that every API goes beyond simple representation, allowing for more powerful usage and analysis.
Gorilla introduces the notion of learning about a retriever, where a custom dataset with instructions includes an additional field to reference the retrieved API documentation. This approach aims to teach the LLM to analyze and answer questions based on the documentation provided. The authors show that this technique allows LLM to adapt to API documentation changes, improving performance and reducing hallucinatory errors.
In conclusion, users provide requests in natural language. Gorilla can operate in two modes: zero shot and search. In zero-shot mode, the request is fed directly to the Gorilla LLM model, which returns a recommended API call to complete the task or goal. In search mode, the retriever (BM25 or GPT-Index) retrieves the most up-to-date API documentation from the API database. This documentation is related to the user request along with the message by referring to the API documentation. The concatenated input is then passed to Gorilla, which issues the callable API. Quick tuning is not performed in this system beyond the connection step.
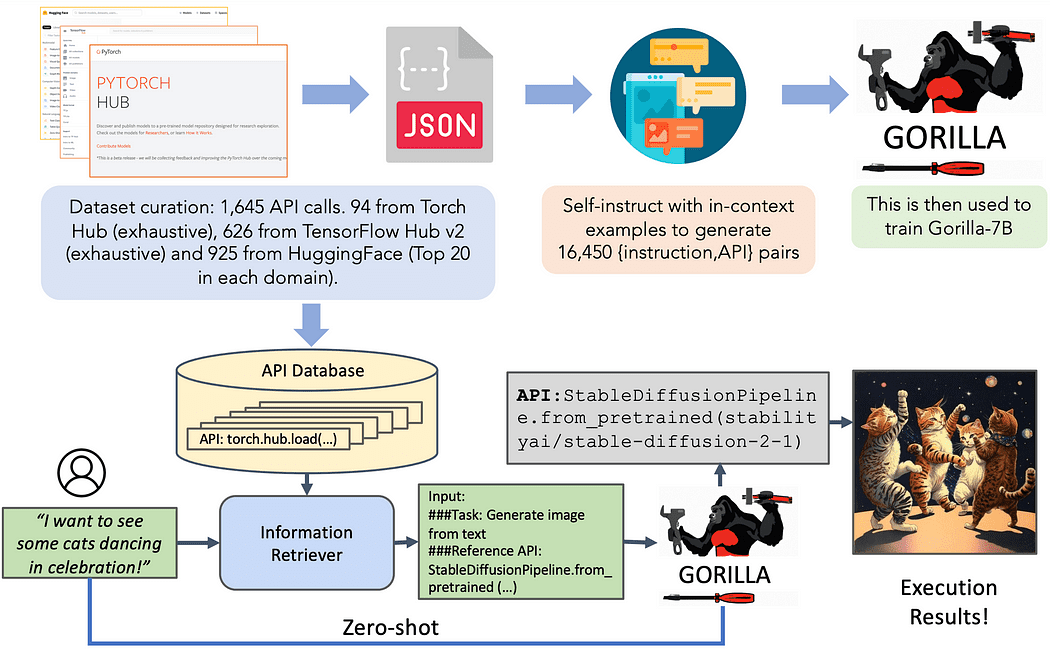
Image credit: UC Berkeley
Inductive program synthesis has succeeded in synthesizing programs across domains that meet specific test cases. However, when it comes to evaluating API calls, relying only on test cases is not enough, as it becomes difficult to verify the semantic correctness of the code. Consider the example of image classification, where more than 40 different models are available for the task. Even if we narrow it down to a specific family like Densenet, there are four possible configurations. Consequently, there are multiple correct answers, making it difficult to determine whether an API in use is functionally equivalent to a reference API through unit tests. To evaluate the performance of the model, their functional equivalence is compared using the collected data sets. An AST (Abstract Syntax Tree) tree matching strategy is used to identify the API called by LLM in the dataset. By checking whether the AST of the candidate API call is a subtree of the reference API call, it is possible to determine which API is being used.
Identifying and defining hallucinations is a significant challenge. The AST matching process is used to directly identify hallucinations. In this context, a hallucination refers to an API call that is not a subtree of any database API, essentially calling an entirely imaginary tool. It’s important to note that this definition of hallucination is different from calling an API incorrectly, which is defined as an error.
AST sub-tree matching plays a crucial role in identifying the specific API to be called in the database. Since API calls can have multiple arguments, each of these arguments must match. Additionally, given that Python provides default arguments, it is necessary to determine which arguments are appropriate for each API in the database.
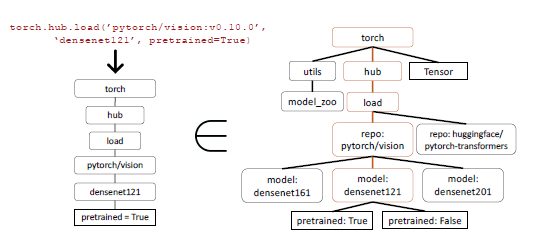
Image credit: UC Berkeley
Along with the paper, the researchers created an open-source version of Gorilla. The release includes a notebook with many examples. In addition, the following video clearly shows the magic of gorillas.
gorilla_720p.mp4
Gorilla is one of the most exciting approaches in the tool-enhanced LLM space. Hopefully, we’ll see the model distributed in some of the major ML hubs in the space.
Jesus Rodriguez He is currently the CTO of Intotheblock. He is a technology expert, executive investor and startup advisor. Jesus founded Tellago, an award-winning software development firm that helped companies become great software organizations by leveraging new enterprise software trends.
Original. Republished with permission.
[ad_2]
Source link